The Changing Sound of Music: Approaches to Studying Recorded Musical Performances
by Daniel Leech-Wilkinson
8. Expressive gestures
8.1. Performance expression
¶1 We’ve seen quite a lot of examples of performance style, and of the way it has changed, and we’ve thought a bit about why. But what is it? What defines it in sound? And how does it work?
¶2 A style isn’t easy to define fully, though it’s easier in music than in most other domains. Think of the difficulty of precisely defining style in painting or clothing, for example: at least in music it’s easy to measure the constituent elements—the sounds—and because they come in sequence you don’t have to consider them all at once. But even so there is still the problem of drawing boundaries between styles. As we’ve seen in talking about period and personal styles, a performer does some things that all performers do, and some that all performers at any one time do, as well as things that some do but not others, and things that only she herself does. To know which level we were defining we’d have to be able to say which of these stylistic features belonged to each. And to do that properly would require a database of all recorded performances and a means of analysing the data. Nicholas Cook and Craig Sapp have been doing something along these lines for recordings of Chopin mazurkas—we looked at some of the techniques in chapter 6—and have made real progress in turning recordings into machine-readable data and developing software routines that can sort through them. The better we get at that the more useful things we’ll be able to say about performance style with real precision. In the meantime we can make some worthwhile progress simply by determining what sorts of things constitute a performance style and by looking at examples of them in practice.
¶3 Let’s start with a simple definition. Performance style is generated by what performers habitually do with the notation to make a musical performance. This is a convenient generalisation if we’re talking about classical music. Actually we don’t have to define it in relation to notation; but there has to be something that is being shaped in consistent ways for there to be style. Let’s take a more extreme example to clarify the point. Jazz uses very little notation: its common material, the bases for performances, are often no more than simple melodies whose precise details no one may quite agree about. But nevertheless they exist recognisably—you know them when you hear them—and it’s their elaboration that makes a performance. All that elaboration is stylistic. The performer plays and elaborates the core materials by bringing to it a manner of decoration, harmonisation, timing, pitch adjustment, dynamic shaping that could equally well be applied to many other melodies. In jazz, variations of tempo and pitch and dynamic are everything. The style is to a very large extent the music. But except for the fact that jazz players feel freer than classical musicians to make their own contribution to the harmony and melody, what makes jazz jazz are precisely the things that we’re looking at in studying classical music performance. There’s a ‘text’ and there is elaboration of it as it is realised in sound. And the way that elaboration is done constitutes the performance style.
¶4 If we want to define a performance style, then, we’re going to need to look at everything except the given material, which for classical music is the notation. We can test this definition by looking at a literal performance of the notation, which if this definition is correct should have no style. Listen again to Sound File 3 (wav file) from chapter 2 and see what you think. We still have the composition style, but it doesn’t make a great deal of sense. Perhaps the MIDI piano is contributing a minuscule sense of shaping to each note by its attack, which someone has programmed to sound like a person playing a piano. But there’s not a lot left that we can easily recognise as musical. What do we mean by musical? Performance style and musicality are essentially the same phenomenon, except that ‘musical’ adds to performance style the notion of persuasiveness. Like performance style, ‘musical’ means the ability to play notes in ways not specified precisely in the score, but it also means doing that convincingly. So performing musically, or stylishly, involves modifying those aspects of the sound that our instrument allows us to modify, and doing it in a way that brings to the performance a sense that the score is more than just a sequence of pitches and durations. ‘More’ in what sense?
¶5 The answer is key to music-making. For perceptual reasons that will become clearer as we go along, these elaborations of the raw instructions in the score, including the modifications of the literally notated lengths, pitches and loudnesses, have the effect for the listener of making the music expressive. By making a note the wrong length (by not doing exactly what the notation says) we change it from a pitch with a duration into a sound that moves us in some way. How a sound modifies our emotional state is a big subject; we’ll find some answers being suggested by the effects we see in our examples. Ultimately it is a problem for neurology and psychology and for empirical study. But for the moment we can approach a general understanding of what happens by considering it as a music-analytical problem in which we interpret the relationship between what we hear and what we feel. And that is what we shall be doing in the rest of this chapter. We’re going to be looking at things performers do in sound and trying to work out how those things affect us as we listen.
¶6 The expressivity we experience through a performance seems to shift all the time, from moment to moment during a performance. One moment may seem to stand out, the next to be more restrained; one note may be rasping, the next softer-edged, and so on; and it seems to follow that expressivity is caused by brief events that happen frequently. One can take any strong example and begin to see relatively easily what kinds of events these are and why they seem to suggest certain kinds of meaning.
-

- Plate 9: Essie Ackland, 'the wave of the golden corn', from Schubert's 'Die Allmacht' (1932)
¶7 Listen to this example. (Sound File 26 (wav file)) 1 It’s from a performance of Schubert’s ‘Die Allmacht’ recorded (in English) by Essie Ackland in 1932; she’s singing about the presence of God in all things. Here the words are ‘see’st it in the wave of the golden corn’. I’m interested in how she sings ‘the wave’. It’s unmistakably wave-like, but how does she do that? The spectrogram shows an outline of what she does; slowing down the recording (using Sonic Visualiser, of which more below) gives us more aural detail (Sound File 27 (wav file)). As she sings ‘the’ she lets the pitch glide from the notated G down to E. Then there is less clearly pitched sound as she moves her tongue from the ‘uh’ position of ‘the’ to the ‘wuh’ of ‘wave’, which passes through ‘rr’ somewhere around C. (This seems curious to us, but a Scottish inflexion of ‘the’, ending with the tongue curving round to ‘rr’, was common in early 20th-century English singing.) The ‘w’ starts around D and glides more slowly up to the notated F becoming the ‘ay’ vowel on the way at about E-flat.
¶8 That’s a rather detailed description of an effect that is perceived more holistically as a wave-like start to ‘wave’, which as the spectrogram shows is exactly what it is. The wave motion covers far more pitches than the two notated (G and F for ‘the wave’), so this is very clearly something brought by the performer to the notation. And it produces a sounding image of the word in the text. Although it’s a wave in sound rather than in golden corn, our brains easily map the sound image onto the visual image and perceive them as equivalent. It’s a metaphor, but not an abstract literary one, rather a real mental effect as the brain makes a connection between one kind of wave and another. Adding one to the other makes the text’s wave more vivid. We feel more of that wave than we would without the sound image: indeed, without the sound image we probably wouldn’t feel it at all unless we had a particularly vivid imagination. So the music is doing some extra work for us, forcing us to perceive that wave whether we want to or not.
¶9 We have in this little example a complete demonstration of the process by which performance expressivity works. The performer does something to the sound not specified by the musical structure. What he does the listener’s brain analyses, as a normal part of the process of ‘perceiving’ sound. In one of many complex processes—involving the analysis of pitch, loudness and timing, and the construction from them of best guesses as to the sound’s source and meaning—the brain searches for similarities between those features and things it already knows about, and sends back into consciousness (which may simply mean that these are the strongest matches found) perceptions of those things that seem to match best. Since it’s getting incoming information from the text about waving corn, that match is made most immediately, along with memories of wave shapes and waving in general, pictures of golden corn, and whatever else each of us may individually associate with these sounds and images. Some kind of mental picture of the singer, based on the sound of her voice and what we imagine of the environment in which people sang like this may be mixed in more weakly.
¶10 What all this amounts to is a sense that this passing moment has meaning, of which the sounds are expressive. It’s meaning and expressivity that is not inherent in the score but that arises from the performance. And the things the performer does to construct this meaning expressively are elements of her performance style. She does them like this because they are consistent with her own manner of being expressive in performance. In Ackland’s case they are relatively strong because that was the norm in her day, and especially in performances of religiose songs in English for a general music-loving audience. (The disc was issued in HMV’s popular series C, part of the cheap ‘plum label’.) Ackland is gauging an appropriate stylistic context within which to pitch this performance. Then she is using her own imaginative responses to the text, calling up images in vision and using her voice to convert those into similar motions in sound. She doesn’t need to think this out in detail. Our brains work fast enough to manage largely through feelings this process of finding appropriate metaphors and generating sounds to represent them, which it can do in microseconds, far too fast for us to think much about. The singer draws on experience, both of singing and of sounds in life, to shape her singing in ways that feel right for the musical and textual moment. That both the making and the perceiving of these effects depends on feelings more than thinking only serves to integrate the process more fully with our emotional state, which is mainly what music modulates when we listen unanalytically (that is to say, normally) to a performance.
¶11 The whole process depends on our naturally selected ability to make connections within and between incoming data streams, generating perceptions of the world outside us that enable us to react appropriately in the interests of survival and reproduction. Survival and reproduction may seem rather far from performing Schubert’s ‘Die Allmacht’, but we respond to sounds in this way because over time it’s enabled our evolutionary ancestors to react usefully to sounds around them, enabling them to distinguish with minute precision between the meanings of one sound and another.
¶12 I’ve allowed this description to go so far into perception and evolution because they are both fundamental to our normal everyday responses to music, and a lot of musical performance effects can only be properly understood in this context. Music is so powerful not because it’s a set of codes invented by individuals over that past few centuries that we’ve all been required to learn—that couldn’t make it powerful, only familiar—but because it uses naturally selected responses, most of them long pre-human, and uses them automatically without waiting for our conscious mind to work out what’s going on. 2 No wonder, then, that expressive performance brings so much to music, indeed is essential to bring music to life. And ‘to life’ is the right metaphor, indeed it’s hardly a metaphor at all, because that is exactly what expressive performance does. It brings life to composed structures which without it exist only as ideas sketched out in notation.
¶13 It’s easy to see how this process connects with the discussion of music and performance in chapter 2. Compositions become music when performers link notes with sounds, shapes, and processes we know from life. The way performers link them is strongly influenced by performance style. Using metaphorical practices common to their place and time, performers inflect notes in order to make them expressive of feelings, and thereby to bring them meaning. We can think of these inflections as expressive gestures, expressive because they represent meaning, and gestures because they shape notes over time in the same way, and for the same purpose, that humans use their hands and face to communicate information about the dynamic shape of a process and about its effect. 3 The metaphor of shape is absolutely fundamental to musical communication. Music makes shapes in sound over time: sounds gets higher or lower, louder or softer, faster or slower, and their timbre changes, and each and all of those processes we understand as shaping sound. There may be a spatial element in our perception as well—that remains to be demonstrated, but it is a possibility that needs testing. At any rate, it’s exactly this changing of any or several parameters of a sound that does the expressive work in performances, so ‘expressive gesture’ seems as good a way of labelling these inflections as we are likely to find.
¶14 There’s one other point that needs to be made before we go on to look at many different examples of expressive gestures from recordings. How large these gestures are, and so how obvious to the listener, varies over time with changes in period performance style. Early in the 20th century, especially during the 1920s and 30s, they were very large; later, especially in the 1960s and 70s, they were often very small, barely noticeable in casual listening although one would notice at once if they were missing. In our own time gestures are typically still a lot smaller than in Essie Ackland’s day, but I’ll be focussing on her period to an unrepresentative degree because it’s much easier to understand the process if we begin with the strongest examples. For listeners today, especially for academic listeners who’ve been trained to search for unobvious meanings in music, things no one has noticed before, performance gestures this large and with metaphorical associations this obvious can be embarrassing or seem trivial. But that is simply a measure of the emotional distance between us and pre-War listeners which we’ve already seen in chapter 4. In due course we can begin to work on more recent performance styles where shaping is far more subtle and far more to our taste. But if you don’t like overtly expressive performance you’ll have to bide your time. We need to know what kinds of processes are involved in musical performance before we’ll be able to see them more subtly at work.
¶15 An expressive gesture can be defined as an irregularity in one or more of the principal acoustic dimensions (pitch, amplitude, duration), introduced in order to give emphasis to a note or chord—usually the start of a note or chord. Expressive gestures involve sounding notes for longer or shorter, or louder or softer, or in some other way different compared to the local average. Why the local average? Carl Seashore, and many who have followed him, described these irregularities as deviations: ‘the artistic expression of feeling in music consists in esthetic deviation from the regular—from pure tone, true pitch, even dynamics, metronomic time, rigid rhythms etc’. 4 The problem with that word is not only that it implies deviance, but also that it seems to suppose that there is a proper length, loudness, or pitch for a note. In terms of the score there may be, but as we’ve repeatedly seen the score is not the music, and nor is a straight performance of it. So ‘deviation’ from the score is normal, in fact definitive of a musical performance, and it’s not the fact that notes are not strictly as notated that generates expressivity. Rather it’s how much they differ from their surroundings and from what we’ve come to accept over the last few moments of listening is the (local) norm. Difference from the score is not what’s expressive; change is.
¶16 So in musical performance, these changing loudnesses, timings and frequencies work together locally, coordinated with the composed melody and harmony, to shape the sounding music; and it’s a shape that consists mainly of alternating, sometimes overlapping expansions and contractions. There are no fixed patterns, and no fixed functions—everything depends on context. Gestures are combined together and placed in sequence to give an expressive shape to a phrase of music, and phrases in turn can work expressively within larger passages of music. But for the listener most of what counts happens in the present, at the ‘now’ moment; and that deserves more of our attention, I’d suggest, than our music-analytical training, with its emphasis on long-term patters, leads us to expect. It’s around the now moment that our consciousness of expressivity is most fully operational, and so it’s the local norm against which gestures are perceived as expressive. 5
¶17 How did expression become so crucial in western art music performance? First, we shouldn’t necessarily assume that it’s absent elsewhere. Rock music is highly expressive, albeit in more consistent ways within each song (rather like early music), not using the moment-to-moment shifts of mood characteristic of art music. So are many world musics, and in a variety of ways. Perhaps what expressivity in western art music (WAM) does is to replace one kind of bodily engagement with music, typically in non-WAM contexts dance, with another, a kind that allows listeners to sit still in rows and still have a deeply satisfying emotional experience, internalising bodily engagement with the music. Expressive gesture in sound may do what physical gesture used to do, and still does elsewhere, and the close relationship may still be suggested by our strong inclination to call it ‘gesture’. It’s been turned into sound to suit a culture that thinks of music as something needing full attention, cutting out visible actions as distracting, a by-product of which has been the tendency of music as sound to become, at any rate until recently, ever more complex. Expressivity has less of a role in the performance of minimalist scores, and we may not be far wrong if we assume that it is closely tied to the nature of musical composition as it developed from the late 16th to the end of the 20th century. Of course, without sound recordings we shall never know.
¶18 As I have said, expressive gestures are not fixed. Any kind of departure from regularity can be expressive. But only a limited palette of gestures is used by one performer, and only a limited set is in use in any period. This is what makes it possible to use a repertoire of gestures to define an individual’s or a period’s performance style. So a 'performance style' is a set of expressive gestures characteristic of an individual performer that taken together constitute their 'personal style'; or a set characteristic of a period ('period style'), or a group (for example, national style). Over time, the gestures that constitute a period style change. One hundred years of evidence is not much, and it’s far too soon to say whether they work to any substantial extent in cycles, or whether the process of change is to all intents and purposes continuous. What we have seen in previous chapters gives us some reason to suspect that the same gestures are perceived somewhat differently in different periods. Although they may invoke quite basic perceptual processes, the precise signification of an expressive gesture must depend on its context to a very significant degree, and this is another reason to be wary of any kind of dictionary of performance gestures that seeks to fix meanings: it is essential to be sensitive to the local and period context in assigning any kind of meaning to a gesture, and to localise that meaning within a particular performance. The one general law we can be confident about is that a gesture makes its impact in proportion to its size, that is, the degree to which it changes what was going on before.
8.2. A methodology for studying expression and expressive gestures
¶19 For this kind of study we need first of all a way of observing gestures at work in their full sounding context. And we need to be able to examine them in more detail than our ears allow. At the least, we need a way of training our brain to hear more precisely. A means of measuring, to enable precise comparison, would be helpful.
¶20 One can do a lot just by listening closely. We do need to be able to listen to the same passages repeatedly, so some means of storing a performance and of replaying it, and parts of it, easily is essential. You can do this with a CD player, but you can do much more with a sound file on a computer. Computer files are far easier to navigate, and you can have several open at once and switch quickly between them, which makes comparisons possible. So I’m going to assume in what follows that importing recordings into a computer, and listening to them and viewing them there are possible. We’ll make fuller use of the computer’s sound capabilities later on, but first I’d like to recommend the virtues of close listening, allied to notation, pencil and paper.
¶21 You can practise close listening; in fact it requires practice, focussing one’s full attention on the sound of the performance. After a time it’s surprising how much detail one can hear, far more than in casual listening. Time spent with the visualisation software we’ll use below will help you to know what are the acoustical components of the sounds you hear, and you’ll be increasingly able to describe instruments and voices, and momentary effects, in acoustic as well as in metaphorical terms. This isn’t the natural place for an introduction to basic acoustics, but if you’ve not had one you need it now. If you have, then skip to the next section.
Basic acoustics
¶22 All natural sounds are made up of several wave forms of different periodicity sounding together. 6 For a musical pitch this typically consists of a fundamental—whose frequency corresponds to the pitch you think you hear—plus a number of higher frequency sounds of which you’re not consciously aware (the brain mixes them all together for you) but which provide all your perceptual knowledge of the timbre of the sound. All these frequencies are ‘harmonics’ (or ‘partials’), and the relative positions of all those above the fundamental are fixed in relation to it. The first harmonic is the fundamental itself, the second an octave above it, the third an octave and a fifth (a 12th) above, the fourth two octaves, the fifth two octaves and a third, and so on, up the harmonic series. 7 The higher they go the closer together they get and the more dissonant they become. Most—typically all—of the ‘overtones’ are quieter than the fundamental, but the louder the highest harmonics are the brighter the timbre of the sound. So brightness is caused by the dissonances among the upper harmonics. If there are few harmonics, or they get soft as they go up the scale, you’ll perceive a smoother, less strident sound.
¶23 Frequencies are defined by the number of cycles of the wave per second. Modern concert-pitch A above middle-C cycles 440 times per second. The number doubles with each ascending octave, so the A above is 880cps or Hz (named after Heinrich Rudolf Hertz), A below concert A is 220Hz. And so on. That means that as you go up the frequency spectrum the number of cycles per second quickly gets very large indeed. Young people can hear between about 30 and about 20,000Hz, but the ear is not able to distinguish between that many different frequencies, and as sounds go up the spectrum the ear is less and less able to tell them apart. It groups adjacent frequencies together into bands, and gives the brain information about each band, but not about the frequencies inside it. So sounds very high up seem less dissonant to us that they might if we had sharper hearing. We’ll need to know this later on when we start to look at sounds on computer displays. For similar reasons to do with the economical construction of the human ear, louder frequencies may mask quieter frequencies nearby, so we don’t hear all the frequencies that machines can tell us are actually present in a sound. And this is another reason why music may sound more mellifluous to us that it otherwise might.
¶24 The other thing that for music perception is crucial about human hearing is our ability to distinguish sounds of different lengths. We can tell the difference between the length of two sounds to within about 30 milliseconds difference, that’s 0.03 seconds. 8 Anything smaller than that we probably won’t notice if it comes within a sequence of other sounds. We took account of this in chapter 6 when looking at Fanny Davies’s rubato and in chapter 5 when looking at our concerto violinists’ portamento, and we’ll come back to it when we look at spectrograms in a moment. Now we can go back to close listening.
Close listening
¶25 It’s possible to do a certain amount of work using just a score, pencil and paper, and your ears (and brain). In fact it’s an important exercise, because it’s all too easy to be led into hearing things one can see on a computer screen but can’t perceive without one. Just listening, and writing down what one hears, is often a very good way to get started when studying a performance. It’s a good idea to be methodical about one’s close listening and so the next group of examples suggests a way of keeping notes.
-

- Figure 17: Marcella Sembrich, Nigel Rogers and Peter Schreier, Schubert, 'Wohin?', bb. 35-45
¶26 Figure 17 annotates the vocal line of an extract from Schubert’s ‘Wohin?’ (the second song from Die schöne Müllerin), in order to indicate, using notation and some fairly self-explanatory signs, how the three singers compared here shape and colour their part. You can follow it with the sound files. There’s no agreed system for making the annotations, so one just has to be as clear as possible.
¶27 Sound File 28 (wav file): Marcella Sembrich (1908) 9
¶28 Sound File 29 (wav file): Nigel Rogers (ca. 1975) 10
¶29 Sound File 30 (wav file): Peter Schreier (1989) 11
¶30 Table 5 suggests a way of organising comments on a number of obvious aspects of the performance style. In each case the most important features, those that seem to do most of the expressive work, are highlighted. It’s now easy to see how the focus of singers’ attention appears to have shifted through the generations represented here (turn-of-the-century, HIP, and modern) from portamento and rubato, through articulation, to text illustration. I say ‘appears’ because first of all these singers have to be shown to be representative: for that a large number of examples would be necessary. In fact it might well be argued that Peter Schreier is exceptional, closer to Fischer-Dieskau in his treatment of text than to most singers of today. So one has to be careful about the kinds of conclusion one draws if one has only a few samples to hand, and this is true, needless to say, whatever approach one takes to studying performances.
-

- Table 5: Making notes on performance parameters
¶31 To get much further into details of sound one needs technological aids. I’ve said earlier that at present much the best way of listening to a passage over and over is to have it in a computer sound editing package, selecting the passage and either playing it alone or setting the play control to loop it, so that it repeats over and over. Another thing a sound editor can do that is invaluable is to align several different performances in a single window, allowing us to switch between them as they play.
¶32 At the time of writing an ideal freeware audio editor is Audacity. Open the program, then, using File > Open , open Sound File 13 (wav file), Elena Gerhardt’s 1911 ‘An die Musik’ with Arthur Nikisch. Then select File > Import and import Sound File 31 (wav file), 12 Gerhardt’s 1924 recording of the same song, accompanied by Harold Craxton. You should now have one above the other. If you press the Play button at this point Audacity will play both together. To listen to them individually, and switch quickly from one to another, either press Solo on the track you want, or Mute on the track you don’t. Pressing Solo is of course the quickest way to switch, but Mute can be useful when you have more than two tracks and wish to hear some but not all of them together. If you want to hear exactly where the differences are you can align the two tracks so that the performances coincide exactly at any point you choose, then play them together to hear where they start to differ. To do this, select the Time Shift tool (the button is in a small panel of six just to the right of the Record button, and is marked with a two-way arrow: ↔). Then if you place the cursor on one or other track you’ll be able to move it left or right. To play both tracks together make sure that neither Solo nor Mute is selected.
¶33 To make the comparison easier I’ve matched the pitches of the two transfers, reducing the 1924 by 74 cents (which of course makes it a little slower too, though not nearly as slow as the 1911). 13 Listening to these two performances side by side proves to be very interesting, and shows us similarities that it would be much harder to hear by listening to one CD at a time. By switching back and forth between the two we can quickly realise that although the rubato is very different, the way she shapes the notes with vibrato and loudness is not. It’s actually almost the same performance except that (and it’s a big exception) her rubato, though considerable, is nothing like as great in 1924 and has a somewhat different character (it’s not just proportionately reduced). It’s a modernised performance in that single respect. 14 And this gives us a very useful clue as to the way attitudes had already changed. Rubato was still very much part of current style, but not to the same almost dangerous extent (dangerous because the performance was always on the verge of stopping altogether) as in 1911. Although it’s so different, Gerhardt’s later recording, when studied closely like this, actually confirms the tentative suggestion made above that performers’ ways of approaching pieces tend to remain relatively stable through their adult lives.
¶34 We can see, using the same technique, another very striking example of this in Sir George Henschel’s two recordings of Schubert’s ‘Das Wandern’, made in 1914 and 1928. 15 (We looked at his 1928 performance, as well as at its coupling, ‘Der Leiermann’, in chapter 4.) The CD reissue by Cheyne Records of the 1914 HMV performance is lower and slower than either their or this book’s transfer of the Columbia 1928 version. 16 (You can hear ours (by Andrew Hallifax) in Sound File 14 (wav file).) To enable the comparison I slowed down our transfer of the 1928 so as to reduce the pitch by 110 cents. Once the pitches match, so do the speeds (which suggests that at least one of the transfers was wrong), and the two performances are almost identical. Only some rubato differences in the piano interludes, and at two of the ‘echo’ phrases that end each stanza, cause the two to get out of synch. It might be tempting to suppose that 1928 was a dub of 1914, but in fact we have a control against which we can test. By matching the pitch/speed of my transfer of 1928 to the Cheyne version of the 1928 recording (a reduction of 28 cents in mine), and running the two simultaneously, one can easily see that here we have two performances that are genuinely identical: there is no variation in any detail, save only for a momentary speed fluctuation in the middle caused probably by an instability in one of the turntables. This gives us a measure, and enables us to use the 1914/28 comparison to say with certainty that Henschel was able to give almost but not quite identical performances fourteen years apart. 17 We’ve seen something similar, over almost thirty years, in Cortot’s recorded performances of Chopin’s E minor Prelude, back in chapter 6. 18
¶35 This is really very fascinating. It’s an article of faith in most discussions of music-making that every performance is different, and so they are; but it’s also important to know that, when a performer plays a well-loved piece over and over in recitals and studios for years on end, their performance settles into an almost unvarying ritual. It is possible, then, to give substantially the same performance twice, indeed more than twice; how unusual that is remains to be seen from further studies. 19 (One must admit, too, that this is a composition that invites a very regular performance!) Experimental evidence suggests that memory for musical tempo is extremely stable, not unlike absolute pitch but in the time domain. 20 That being so it would not be surprising if expressive gestures in which rubato was a significant component were easily memorised and reliably reproduced over long periods of time.
Tempo mapping
¶36 We’ve seen several detailed examples in chapter 6 of tempo mapping in practice, and it’s easy to see from them why tempo rubato is such a powerful means of expression. There’s been a lot of research on this in recent years, with many studies by musicologists and psychologists charting tempo change in performances of orchestral and piano music. 21 It’s well established, therefore, that tempo is worth studying closely. To date, three main expressive functions of tempo rubato have been investigated: tempo changes to point up compositional structure; to bring life to a performance; and to differentiate between more and less intense feeling. Naturally all three are related, but we’ll look at them in turn.
-
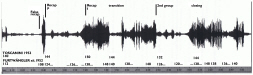
- Figure 18: Wilhelm Furtwängler and Arturo Toscanini, Beethoven 3rd Symphony, 1st movement, recapitulation: tempi
¶37 1) Tempo changes to point up aspects of compositional structure. Nicholas Cook has looked closely at this in two of Furtwängler’s recordings of Beethoven’s 9th Symphony (1951 and 1953), comparing them to Schenker’s analytical prescriptions for performance, and has shown how varied and how subtle are Furtwängler’s responses to the relative weight of different structural features in the score. 22 By the time these recordings were made it was already unfashionable to respond in such detail. Toscanini, whose manner was far more influential on younger conductors, chiming with modernist preferences, 23 took a more literal approach, but still one that responded carefully to the main structural divisions. We can see the contrast between Furtwängler’s and Toscanini’s approaches in recordings of Beethoven’s 3rd Symphony made only months apart in 1952 and 53. Figure 18 maps the chief tempo changes in the exposition of the first movement, which can be compared to the changes in loudness indicated by the depth of the waveform. While both conductors use tempo rubato to point up structural features of the score, it’s very obvious that Furtwängler uses it much more often and more flexibly, an approach that turns out in retrospect to seem old fashioned simply because in more recent times conductors have become ever more literal in their realisation of scores, as José Bowen’s comparative study clearly shows. Bowen examined a large number of performances of Beethoven’s 5th and found a clear trend towards slower speeds, despite the first-movement second subject gradually ceasing to be played slower than the first. 24 We also saw in chapter 6 examples of Fanny Davies deploying bass anticipations, which are rather complex instances of rubato acting at different rates in right and left hands. And in the examples of Ilona Eibenschütz and Alfred Cortot there were many points at which the compositional structure was being laid out before the listener. It happened much less later in the 20th century, as audiences were expected to work harder to understand the music by themselves.
¶38 2) Tempo changes to bring life to a performance. In a sense that is exactly what all these performers were doing; but it happens on every level, not just the structural. Sounds that are absolutely regularly spaced are not natural: if we hear them in life we attribute them to machines. Humans, as we shall see when we look at tapping along to recordings, are not capable of completely accurate timing, and the notion that slight irregularities in the appearance of things are indications of natural growth is so built-in to our perception of the world that it’s entirely understandable that we should see them as beneficial in musical performance. The influence of body respiration and pulse is obvious. So when we look at a sequence of equally spaced notes and find that they are not equally spaced at all, we may be seeing evidence of human imperfection, but we are perceiving humanity made sound and appreciating it. Sound File 32 (wav file) is Benno Moiseiwitsch’s 1948 recording of Chopin’s Prelude in C minor, Op. 28 no. 20. 25 Figure 19 maps the beat lengths. The chords sound even, and yet it’s not dull, and that’s because (as well as changes in loudness) Moiseiwitsch is lengthening the beats we expect to be lengthened, 26 especially the third of each bar, and because of the graduated lengthening of each four-beat group through the first first-bar phrase, gradual enough that we don’t notice it unless we’re listening very closely indeed. The patterns in the next four-bar phrase and its repetition are slightly more complex but make sense in relation to the score. So the performance is far from mechanical, despite its apparent regularity; in fact, it seems alive. We looked in chapter 6 at examples of Chopin’s Berceuse, emphasising the vital importance in any performance of using rubato to allow the ostinato accompaniment to ‘breathe’, and we can see now why that metaphor is appropriate.
-

- Figure 19: Benno Moiseiwitsch, Chopin, Prelude in C minor, Op. 28 no. 20, bb. 1-12, beat lengths
¶39 3) Tempo changes in order to map intensity of feeling. For equally ‘natural’ reasons, making metaphorical connections between musical sounds and shaped experiences we know from life, tempo change can very well model changes in intensity of feeling. An increase in speed in most contexts signals an increase in excitement, metaphorically linked to faster beating heart, faster breathing, faster locomotion. A decrease in most contexts will signal the opposite. Similarly, slowing tempo, combined with other signals, can indicate intensification of painful or loving emotion, modelling the way our attention and energy is drawn away from anything we may be doing with our bodies and channelled into the experience of emotion the deeper that is. Elena Gerhardt’s ‘An die Musik’ at the start of chapter 4 was a very strong example, as her performance ground almost to a complete standstill at the high-points of phrases and we understood her to be overwhelmed by the intensity of her feeling about music. We’ve seen many examples on a much smaller scale, including the subtle rubato of Patti and Joachim, the more explicitly emotional narratives of Lotte Lehmann, in which tempo change plays a large part, and the endlessly varying rubato of Cortot. Rereading the discussion of Cortot’s playing of Chopin’s E-minor prelude, Op. 28 no. 4, from chapter 6 at this point will help to show how effectively finely-calculated tempo change can effect our perception of music in performance, as well as the extent to which changes in tempo and changes in loudness are intimately bound up, something worth bearing in mind whenever one does a study of tempo on its own.
¶40 On other point to bear in mind before we look at how to map tempo change is that it is the one mode of expressivity that is available to all instrumentalists. In extreme cases, outstandingly harpsichords and organs, players can do nothing else at all to be musical than vary the length and onset timing of notes; and so these instruments make especially good subjects for study if one wants to understand how rubato can work (assuming one can find a player capable of managing them, easier with harpsichords than organs because the action is that much more precise). Another very interesting subject, as yet wholly unstudied, would be the basic form of player piano, in which the notes are provided by the roll, and the player is left to focus entirely on modulating tempo to generate expressivity. I offer these as suggestions for readers to pursue.
Mapping tempo
¶41 You can do a certain amount of general work on tempo simply using a metronome. It’s far from ideal, but if you follow a performance enough times, focussing on one section at a time and adjusting the metronome’s speed to the tempo at that point, you can assemble a rough map of tempo change through the main sections of a performance. Because you need more than a couple of beats to fix the metronome, it’s not going to show you how tempo shifts from beat to beat. For recording the exact timings between each pair of beats there are currently two common techniques in use. The first, used in most published studies by musicologists to date, involves tapping along to the recording and using a simple computer program to record the time intervals between the taps. The resulting data can then be converted into a graph whose curves show the extent to which tempo is speeding up or slowing down through each beat of the score. The main disadvantage here is that it’s hard to be accurate. To tap exactly on the beat one has to know in advance when it will come, which means a lot of practice runs. In fact it’s best to record many runs, at least five, and average the results, not including any runs with significant errors of which one is aware. Even so, error will arise through mistakes in anticipation and through slow response time from ear to brain to finger to computer processor to RAM.
¶42 The second common method is more accurate but more laborious. One takes a visual representation of the sound file on computer and marks it up at the start of each beat; then one measures the time between each and notes them down or, if the program allows it, the computer records them automatically and exports them to a spreadsheet, where they can be graphed. This way you can be sure that you have the beats in very nearly the ideal places—very nearly because the point at which a beat is perceived to begin is not exactly the start of the sound signal for that note, but for almost all performance analytical purposes this method gives good enough results. This was the method I used in the graphs provided with chapters 4-6.
¶43 I’ve not given detailed examples of how to use either of these methods because there is now a better one that combines the two, provided by the freeware program Sonic Visualiser. (Of course, by the time you read this there may be a better way, in which case use it!) 27 Nicholas Cook has provided an admirably clear introduction to this at http://www.charm.kcl.ac.uk/analysing/p9_0_1.html, which it would be impossible to better, so I suggest that you read it now. The strength of this program is that it enables you to tap in markers which are added to a visual representation of the sound file (which may be either a wave form, which shows loudness and timing, or a spectrogram, which shows frequency as well). Then you can adjust the position of the markers by sight, checking against the sound as the file plays (slowed down if you like). You can export the data to a spreadsheet which will graph it automatically, or you can get Sonic Visualiser to do it and lay the graph on top of the wave-form or spectrogram. This makes it extremely easy to see exactly how a performer is matching changes in timing, pitch and loudness and so gives one a very powerful resource for observing and understanding expressivity in practice.
¶44 Let’s look at an example. I’ll assume that you’ve downloaded Sonic Visualiser (SV) and have it running on your computer, and that you know how to import audio sound files. Sound File 33 (wav file) contains the first large phrase of Elena Gerhardt’s 1911 ‘An die Musik’. 28 Open it in SV (File > Import audio file). You’ll see the recording represented as a waveform. Click on Layer > Add New Time Instants Layer. Press the Play button and tap the semi-colon key on each beat of the performance. You’ll find it hard! When you’ve finished, go into SV’s edit mode by clicking on the crossed arrows symbol on the edit toolbar. Your cursor should become an upwards-pointing arrow. Then you’ll find that you can use that to move your time-instant marks back or forward until you’re happy with their position. You can do this by sight, looking for the loudness peaks at the start of each beat, but you’ll get a more convincing result if you do it as far as possible by ear, because the loudness peaks don’t always exactly match the perceived beats. When you play the file again you’ll find your time-instants sounding as clicks or swishes on top of the music, which makes it slightly easier to decide when they’re in the right place. (You can turn these off by selecting this layer with the vertical-lined tab near the top right of your screen and clicking the small green ‘Play’ button near the bottom right.) My guess is that you’ll never be entirely satisfied.
¶45 You can get a much better result, however, if you use a spectrogram display which shows not only the loudness of each moment but also the frequency of the sounding notes. That way you can see exactly where each pitch begins. We’re going to use spectrogram displays more subtly later on in this chapter, but tempo mapping is another thing you can do with them. So click on Layer > Add Spectrogram. All being well you should see your beats superimposed on it. Play it to see how this works. You may find it helpful to adjust the grey dials at the bottom-right of the display in order to get a more detailed picture. Pull the vertical dial down until the light grey box immediately to its left is about a quarter to a fifth of the height of the whole grey column; then drag the lighter box down to the bottom. (You can get the same result by double-clicking on the dial and then typing in a figure around 4500. All you’re doing is setting the bandwidth of the visible area of the spectrum.) Pull the horizontal dial rightwards until you have plenty of horizontal detail, allowing you to see the individual notes easily. (Or double-click it and enter a value around 50.)
¶46 Now you can see where the piano notes start, and where the vocal notes change. They’re not always in the same places, and you’ll need to choose exactly where to mark the onsets of at least some of the beats (‘hol-‘ of ‘holde’ is a particularly difficult one). Again, try to put the markers where you hear a beat, even if it looks wrong, though you should find that in this display it mostly looks exactly right. Seeing the notes as frequencies really does help, because what you’re looking at here is really a kind of super-score, showing not just the pitches and notional durations but everything that the performers do in sound. If you can’t be bothered with all this, or are having trouble, there's one I prepared earlier at Data File 3 (sv file). If you click on the Time Instants tab near the top right of the screen (tab 2, if you use my file) you should see the beats marked on a moderately clear spectrogram display—moderately clear given that this is a very old recording with a lot of surface noise that the machine faithfully records.
¶47 One difference you’ll notice if you open Data File 3 (sv file) and compare it with yours is that mine has numbered the beats within each bar. You can achieve this as follows. Select the time instants layer again. Select all the time instants (Edit > Select All). Then set up the beat counters for four beats in a bar (Edit > Number New Instants with > Cyclical two-level counter (bar/beat); Cycle size > 4). Finally renumber the beats (Edit > Renumber Selected Instants). All being well your beats should now be numbered 1.1, 1.2, 1.3, 1.4, 2.1 etc.
¶48 Now we can make a tempo graph. With the Time Instants layer on top select all the instants (Edit > Select All), and Copy them; add a Time Values Layer for the graph (Layer > Add New Time Values Layer), and Paste. In the dialogue box that appears select ‘Duration since the previous item’. Your tempo graph should appear. (By all means try the other options in the dialogue box, opening a new time values layer for each, and see what happens. Choosing ‘Tempo (bpm) based on duration since previous item’, for example, will give you a graph that goes up to get faster and down to get slower.) With the new layer selected (tab 4 if you’re using my version) set ‘Plot Type’ to Line or Curve to get a clearer display.
¶49 Use Layer > Add New Text Layer to add in the words at the appropriate places: ‘Du holde Kunst, in wie viel grauen Stunden’. (If you place them inaccurately you can move them by using the crossed-arrows edit tool, just as for the time instants.) Or just open my version at Data File 4 (sv file). If you work your way along the tabs at the top right you should be able to assemble a composite picture that superimposes a tempo graph on the waveform, spectrogram, time instants and text. What we’re left with is something potentially very helpful, a display that shows at a glance exactly how long and how loud each note is, what its pitch is, and how quickly the tempo is getting faster or slower. Just about everything we need to know about the sound of Gerhardt’s performance is on screen, and all we have to do is to start to think about how it relates to the experience of hearing this performance. 29
¶50 One of the very obvious things we can say is that the rubato relates quite closely to the words. The main ritardandi happen on key descriptive words: ‘Du holde Kunst (You lovely art), in wie viel (in how many) grauen Stunden (dark hours)’, and then later on ‘Kreis’ (crisis). Note too the swoops up to ‘holde’ and ‘grauen’, and the way ‘holde’ is shaped by vibrato getting wider and then narrower again, each component of the sound giving that moment greater emphasis. Each in fact could be thought of as a separate expressive gesture, although in practice they combine into one: each brings some expressive value to the whole. The loudest moments in the extract are in ‘wie’ and ‘mich’, both doing expressive work, the former emphasising just how many dark moments have been relieved by music, the latter emphasising how personal this all is (as if we couldn’t tell). Of course the huge extent of the rubato, coupled with the changes of dynamic and the pitch inflections (vibrato and portamento both varying expressively), add up to something far more extreme than we could possibly consider tasteful today, but that’s beside the point. For reasons I outlined in chapter 4, this style made perfect sense to Gerhardt, and surely to at least some of her listeners, as the most intense expression of her love of music that she could communicate. And now it’s easy to see the elements that combine to generate it.
¶51 If she worked on this scale—with modifications of parameters from note to note as relatively large as this—all the time, we might well find her singing impossible. This has to be accepted as a special case, I think (and one which, as we have seen, she moderated somewhat in her later, 1924, recording of the piece). Nevertheless, in studying other recordings by her we can expect to see similar sorts of gestures on a smaller scale—and indeed, in her 1924 recording (Sound File 31 (wav file) above) that is exactly what we get: essentially the same gestures, but reduced in length. Their nature, if not their size, is characteristic of, in fact defines, her personal style, and fits plausibly within her period. A thorough definition of a personal or period style, then, could use these sorts of visualisation techniques to analyse its constituent expressive gestures.
¶52 For contrasting examples of tempo mapping put to use in performance analysis I refer you back, if I may, to chapter 6 and the discussions of Eibenschütz compared to Kempff in Brahms Op. 119 no. 2, and of Rubinstein’s and more recent pianists’ recordings of Chopin Op. 17 no. 4. They were produced by a similar process to that outlined above, though the Eibenschütz/Kempff used PRAAT rather than Sonic Visualiser. You can find ready-made markup files for a great many recordings of Chopin mazurkas within the CHARM website: http://www.mazurka.org.uk/ana/markup/. Select any highlighted recording and you’ll be taken to details of the markup files available. Provided that you have a copy of that recording you’ll be able to import both the recording and the markup into Sonic Visualiser or the freeware sound editor Audacity and use them for performance analysis of your own. Or of course you can start from the beginning, using the procedure illustrated by the Gerhardt ‘An die Musik’ extract and make your own markups on any recordings you may wish to study.
¶53 It’s tempo graphs like these that Craig Sapp has used to generate the graphic comparisons of performances mentioned in chapter 6 when we were looking at the Rubinstein examples. Sapp used a mathematical technique designed for comparing curves in order to compare the graphs of pairs of performances of Op. 17 no. 4. You’ll find examples at http://mazurka.org.uk/ana/hicor/ together with explanation of how they work. The Rubinstein comparisons are particularly interesting because of the clarity with which they show just how alike his 1938 and 1961 performances are. Yet to us, as listeners, they seem distinct, each fitting well within its surrounding period style. The later performance seems (and indeed the tempo graphs confirm this) to use narrower rubato, in keeping with the practice of other pianists active in the 1960s, while the earlier fits well within the habitual style of players in the 1930s. So how is it that Sapp’s maps correlating tempo curves look so similar? Presumably what have remained constant are the places where Rubinstein places rubato, and the extent of it at each spot relative to the overall range of tempo change (which is narrower in 1961). It’s also likely that listeners’ impressions will be affected by the relationship between rubato and changes in loudness which these images do not map. That too is probably contributing to our sense that these performances belong to different stylistic worlds. It’s an example that can tell us quite a lot about how style change works and about how performers develop. Not many change as much as Rubinstein, but even when they do their personal styles, as fingerprinted in these analyses, are still sufficiently constant to differentiate them clearly from anyone else.
¶54 Another thing these images show is the relative uselessness of a measure of average tempo over a whole composition. Not only do all performances look alike when one reduces them to a single measure (the tips of Sapp’s triangles), but one is ceasing to look at them at a level that has anything to do with the way we perceive music. There are questions that are worth asking about these more general levels, especially about the way speeds have changed over the last hundred years, which is what Bowen showed so clearly for Beethoven’s 5th symphony. 30 But on the whole the most fruitful levels for investigation are sufficiently near the surface of a performance (and a composition) to be perceptible with close listening. Sapp’s analyses are particularly interesting because they show all levels: one can read the detail near the bottom and the generality towards the top. (Schenkerians will see the value of that at once.) They suggest just how much there is to be learnt from imaginative visual mapping of performance data taken from recordings. There is surely, in techniques of data analysis like this, huge potential for a new generation of scholars wanting to discover more about how music in performance works.
¶55 A final point before we move on to analyse expressive gestures, a point I’ve hinted at a couple of times but that needs to be made explicit: in most music-making rubato is not just a matter of tempo. Rubato works together with changes in dynamics, and the interrelationship is too complex to be understood as yet (an area that badly needs sophisticated empirical research). Nothing makes this clearer than the examples generated by Craig Sapp and Andrew Earis, using software developed by Earis that extracts the timing information from recordings and applies it to a plain MIDI performance of the score. 31 By this means it’s possible to hear fine pianists’ rubato without its associated dynamic changes. Sound File 34 (wav file) allows you to hear the result, derived from a performance by a very well-known contemporary pianist of Chopin’s Mazurka Op. 17 no. 4. The result, as you can hear, is musical nonsense: there seems to be no reason for notes to be as long or as short as they are. The example warns us that tempo mapping is only part of the story: timing only makes sense in relation to other parameters, and it’s understanding the interrelationship that is the key to understanding performance. It offers us the exciting prospect that there is fundamental research on musical performance waiting to be done.
Spectrographic displays of expressive gestures
¶56 We’re now in a position to focus on the analysis and interpretation of expressive gestures at a relatively detailed level. I’m interested in what makes individual notes or small phrases meaningful, expressive of something. For this we’ll need to use the spectrographic capability of Sonic Visualiser or any other spectrographic software. We need to begin with some introduction to spectrograms, their capabilities and their limitations. 32 Then we’ll be in a better position to interpret what we see. 33 I’m going to start with a very basic description of what you can see in two related examples. 34 If you’ve seen enough spectrograms to understand this already then skip to the discussion of the second, which introduces some useful information about the spectra of words.
-

- Plate 10: Heifetz, Schubert, 'Ave Maria' (arr. violin and piano), matrix A21072, issued on HMV DB 1047 (rec. 1926), 1'04''-1'24''
¶57 Plate 10 is a spectrogram of an extract from Heifetz’s c. 1926 recording of Schubert’s ‘Ave Maria’, arranged by August Wilhelmj for violin and piano. The sound file is Sound File 35 (wav file). 35 If you have Sonic Visualiser to hand you can load Data File 5 (sv file) and use that instead of the picture. 36 On the vertical axis is frequency, indicated by a scale in Hz on the left, and you can see that this picture shows frequencies between 21Hz and 3400Hz (remember that middle A is at 440Hz); on the horizontal axis is time (this extract lasts 19 seconds, which will give you an idea of the scale); loudness is shown as colour, from dark green for the softest, through yellow and orange, to red for the loudest sounds. What you can see here is a map of all the frequencies that sound louder than about -50dB. In fact most of the musical sounds shown are louder than about -30dB, the rest is surface noise from the 78rpm disc which looks like a green snowstorm in the background. Try to ignore that and focus on the straight and wavy lines in brighter colours. The straight lines nearer the bottom of the picture are frequencies played by the piano, though the first note of the violin part is pretty straight too since Heifetz plays it with almost no vibrato. All the wavy lines, of course, are violin frequencies, wavy because of the vibrato which at its deepest is about 0.75 semitones wide. So although the violin and piano frequencies are displayed together, the violin vibrato makes it fairly easy to tell which notes are which. The violin is also much louder most of the time, especially because its notes don’t die away as the piano’s do, so the violin notes are sounding higher frequencies further up the picture. The bottom of the picture is fairly confused, which is quite normal because the fundamentals are relatively close together. We can alter this in SV by selecting ‘log’ instead of ‘linear’: it produces very wide frequency lines at the bottom but at least you can see more easily where the notes are on the vertical axis. Of course it’s along the bottom that the fundamentals are shown—apart from artefacts of the recording (which we have here right along the bottom at 21Hz—ignore those) the fundamentals will normally be the lowest frequencies present and the ones you perceive as the sounding pitches. All the rest of the information on the screen is about the colour or timbre of the sound.
¶58 You should be able to see without too much difficulty that the piano is playing short chords on fairly even (quaver) beats—look at the 473Hz level—and because the display is set up to show evenly spaced harmonics, rather than evenly spaced frequencies, you can see the violin harmonics as evenly spaced wavy lines above, and much more clearly than the piano harmonics which disappear into the snowstorm much more quickly. (There are some visible though at about 600Hz and 750Hz.) Heifetz’s vibrato is quite even, and you can see that the frequencies between about 1500Hz and 2100Hz are louder than those immediately below and above. This is an important element in Heifetz’s violin tone in this recording. The fundamental and lower harmonics are obviously much stronger, giving the sound warmth, but these strong harmonics relatively low down in the overall spectrum give it a richness without the shrill effect we’d hear if these stronger harmonics were higher up. The other feature that’s very obvious is Heifetz’s portamento about three-quarters of the way through the extract.
¶59 Now compare this example with Plate 11. You can find the sound in Sound File 36 (wav file) and the SV setup in Data File 6 (sv file). 37 The SV settings are the same but the two images are not to the same scale.
-
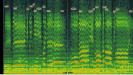
- Plate 11: McCormack, Schubert, 'Ave Maria' (in English), matrix A49209-1 A, issued on HMV DB 1297 (rec.1929), 1'07''-1'28''
¶60 This spectrogram shows a performance of the same extract of the same composition, but now as sung by John McCormack in 1929. 38 What I want to show here is how the words make a very big difference to the sounding frequencies. McCormack sings in English, ‘Safe may we sleep beneath thy care, Though banish'd, outcast and reviled’. His accent is not quite what we’d expect today; my text annotations on my SV file reflect his pronunciation. Naturally the spectrogram shows information about the colour of his voice but it’s extremely difficult to work out where that information is, because most of the patterning in the spectrum of his voice is information about his pronunciation of the words. Acoustically, vowels and consonants are patterns of relative loudness of the sounding frequencies across the spectrum. Vowels are made by changing the shape of one’s vocal cavity, and the effect of that is to change the balance of harmonics in the sound. That balance will remain the same whatever the pitches one may be singing and (though to a lesser extent) whatever the tone of one’s voice—to a lesser extent because the colour of a voice colours the vowels too, making them ‘darker’ or ‘lighter’, and singers can shift vowels around the vocal cavity, making them all darker or lighter, in order to change listener responses. 39 So the visible information in this spectrogram is much more informative about the words McCormack is singing than about the sound of his voice. You can see how similar the spectrum pattern is for the first two syllables, ‘Safe may’, whose vowels are the same. The same goes for ‘we sleep be-’, and between ‘ee’ and ‘be’ you can just see the ‘p’ of ‘sleep’ as a vertical line, indicating the noise element (almost all frequencies sounding for a moment as the lips are forced apart by air) in ‘puh’.
¶61 You can get a feeling for the way in which changing the balance of frequencies changes the vowel if you imitate McCormack saying ‘cair’ (of ‘care’) ‘ar’ (of ‘banished’, which he pronounces as something more like ‘barnished’)—’cai ar’—and feel how close those vowels are in the mouth. You’ll see what changes in the picture as you move from one to the other: just as the vowel moves back and down in the mouth so higher harmonics are stronger in ‘air’ and lower harmonics in ‘ar’, and you’ll sense that as lighter and heavier or brighter and warmer sounds respectively. Similarly if you compare yourself saying McCormack’s ‘(th)’ough’ and his ‘ou’(t-), you’ll feel the movement of the vowel up the throat and the widening of your mouth, and it’s easy to sense how that produces the change in spectrum you can see in the spectrogram: a small loudening of the harmonics from the third harmonic upwards, producing a slightly ‘brighter’ sound compared to the ‘dull’ ‘warmth’ of ‘ough’. It’s a useful exercise that sensitises one to the ways in which harmonics colour sounds of all sorts.
Shortcomings of spectrograms
¶62 Now we know something of what we’re looking at in spectrograms it’s important to know, too, some of the pitfalls in reading them. First, although the computer maps the loudness of each frequency fairly exactly from the sounds coming off the recording—in an ideal recording situation showing how loud each sound ‘really’ is in the physical world—the human ear has varying sensitivity at different frequencies. Any textbook of basic acoustics will include a chart of frequency curves which shows just how much louder (in decibels (dB) which measures sound energy) high and especially low sounds have to be before we perceive them as equal in loudness to sounds in the middle. Our greatest sensitivity to loudness is in the 1-4kHz range (esp 2-3kHz)—probably evolved because this range was useful for identifying transient-rich natural sounds, helping our ancestors identify the sources of sounds in the environment accurately and quickly—but it now makes us especially sensitive to vowels in speech and tone colour in music. Nevertheless our ears seem to hear the fundamental most clearly, because it’s not interfered with by the vibrations of the harmonics to the same extent as the harmonics are by other harmonics, so it’s easier for our ears to identify with certainty (the nerve cells in our ears fire without interference from others firing with different frequencies nearby); but the loudest information is often from the harmonics. If instruments and voices had their fundamentals much higher up the scale, in the 1-4kHz band, music would be a lot less colourful. Similarly, the sensitivity to different degrees of loudness that we need for direction-finding allows us to be aware of this wide range of tone colours that we don’t otherwise need in an evolutionary sense. So that range between about 1-4kHz is important for the information it carries about tone, and we perceive it as louder than the computer does. Consequently a spectrogram doesn’t colour those frequencies as brightly as it would need to in order to map our perceptions.
¶63 Another thing to bear in mind is that the higher up the spectrum you go the more the ear integrates tones of similar frequencies into ‘critical bands’, within which we don’t perceive independent frequencies. For example, 40 a 200Hz frequency’s higher harmonics at 3000, 3200, 3400Hz all fall within a single critical band (3000-3400) so for us are integrated, meaning they are not perceptibly different. There’ll be no point, therefore, in trying to attribute to small details within that critical band any effects we hear in a performance. On the other hand, the auditory system enhances contrasts between these critical bands, so some sounds that look similar in a spectrogram may be perceived as quite strongly contrasting. Moreover, louder frequencies can mask quieter, so that the latter don’t register with our perception at all. For all these reasons (and more), what comes into our ears—which is a reproduction of the same signals that the computer measures—is different in many respects from what we perceive psychologically. 41
¶64 It’s important, too, to be aware that seeing sounds in a spectrum display encourages one to hear them. This can be a very good thing, sensitising one to aspects of sound that one previously ignored. But equally it can lead one to attribute disproportionate significance to visible details. Not everything one sees on the computer screen is as audible as it is visible, and (especially in the case of synthetic effects like timbre) vice versa. So one has to use a spectrogram together with what one hears; it’s not something to be read but rather to be used as an aid to pinpointing features of which one is vaguely aware as a listener; it focuses one’s hearing, helps one to identify and understand the function of the discriminable features of the sound. In this role it’s the most powerful tool we have.
¶65 Sound File 20 (wav file) is Fanny Davies’s recording of Schumann’s Davidsbundlertänze, book 2 no. 5, whose triple layering of melodic lines we discussed in chapter 6. Data File 7 (sv file) is a SV setup which tries to reveal the individual notes as clearly as possible (given the noisy recording). We can use this now (if we have the patience) to measure the exact timings and loudnesses of every note. I recommend playing the SV file a few times to get used to picking out the three layers visually. Then use the mouse and the readout in the top right-hand corner of the spectrogram to get the loudness of each note in dB, placing the mouse-tip on the brightest part of the start of each note. In fact the notes are not strictly layered in loudness nor as evenly played as you might think listening to the recording, but the loudness of each needs to be understood together with its timing, which can also effect our sense of its weight, as of course does the compositional structure which gives notes different perceptual weight in relation to the surrounding melody and harmony. The bass line is consistently quieter, but the inner arpeggiated accompaniment is often as loud as the melody: what makes the melody seem louder is of course its place at the top of the texture and at the start of many beats, whereas the middle voice tends to be quieter at the beginning of the bar and then to crescendo as it rises up the scale through the bar. None of this is at all surprising.
¶66 Much more interesting is Davies’s rubato, of which we can get a vivid impression by using SV’s playback speed control. This is the dial in the bottom right-hand corner. Double-click on it and enter -130 in the box, which slows the performance substantially, and listen carefully. According to the score the notes come evenly on successive quavers. Davies’s second quaver, the first of the inner voice, comes on the fourth (what would be the fourth if she were playing in time at the speed she takes the inner voice once it gets going), which establishes an intention to linger at each new minim beat. After the second melody note she waits an extra quaver before continuing with the inner voice; later this gap becomes about a quaver and half; and now we can hear much more easily just how the inner voice waits for melody and bass at the top of the phrase, and just how much the arpeggiation of the left-hand chords contributes to this miraculously subtle performance. One could map this out as a tempo graph, but actually in this instance one learns a lot more simply by listening at a slower speed, focussing the attention of one’s ears on the placing of the notes one also sees. It’s a powerful aid to understanding.
¶67 We already discussed Benno Moiseiwitsch’s crescendoing piano notes and now we can use SV to see how they work. (Sound File 22 (wav file) and Data File 1 (sv file).) Click on the Select (arrow) tool in the toolbar and move the mouse across the screen and you’ll see an orange ladder whose rungs mark the expected positions of the harmonics of the note at the bottom. If you move the ladder over the any of the crescendoing notes (at ca. 11 secs and 36 secs at 950Hz most obviously, but there are others) you’ll see that treating those frequencies as the third harmonic above the fundamental places the fundamental on a moderately strong lower frequency, whose partials are apparently reinforcing the melody note, causing it to get louder again. Resonances are being set up which cause the melody string to vibrate more vigorously for a moment, and they may have partly to do with that particular instrument or even with the recording room or equipment: it’s interesting that the same B-flat figures twice, suggesting that one of the elements in the sound reproduction chain is particularly sensitive to that frequency. So we shouldn’t wax too lyrical about Moiseiwitsch’s skill in balancing harmonics! Nevertheless, the overlapping of melody notes, hanging onto the last for some while after playing the next, is very clear from the spectrogram and gives one some useful insight into his piano technique.
¶68 Turning to string playing, it’s extremely easy to use SV, or any program that gives a readout of frequency and timing, to measure vibrato and portamento. Sound File 37 (wav file) and Data File 8 (sv file) derive from Albert Sandler’s 1930 HMV recording of Schubert’s ‘Serenade’, arranged for violin and piano. 42 Using SV and the select tool choose a long violin note with at least five full vibrato cycles, and choose a harmonic that gives a large clear display. The vibrato cycles are going to be the same length in time (they’ll have the same rate) and the same width in pitch (the same extent) whichever harmonic you take, but if you have a choice use one of the higher harmonics because the resolution of the spectrogram is better the higher you go. Click on the first peak and drag the mouse along five peaks (ten is better, but in most pieces not many notes are that long). Read off the duration of your selection from the numbers at the top of the selection—it will be around 0.7 secs (the exact length depending on which note you choose, because Sandler’s vibrato rate varies). Simple mental arithmetic (0.7*2/10) will tell you that in that case each cycle takes about 0.14 secs, which gives you Sandler’s vibrato speed at this point (it’s about 7 cycles per second if you prefer measurement in cps).
¶69 Working out the depth (extent) of vibrato is a little more complicated. First of all, with the spectrogram tab selected, change ‘Bins’ from ‘All bins’ to ‘Frequencies’. Set to ‘All bins’ you see the frequency range (the width of the bin) that SV has actually measured; how wide this is depends on your choice of Window size in the box above. There’s a trade-off between accuracy of timing and frequency, so the larger the window size you accept the more approximate the timing information but the more precise the frequency information you’ll get from the display will be. (When you increase the window size increase the overlap as well to recover some of the timing precision.) ‘Frequencies’ gives you an estimate of the frequency actually present in the bin, which lies somewhere within the range SV has measured. So setting ‘Bins’ to ‘Frequencies’ gives you a much more precise display of the frequency SV thinks you are hearing.
¶70 Now using the select tool, place the mouse tip at the top of a typically-sized vibrato cycle. Ideally, get it right on the band of colour representing the frequency; 43 then move the mouse down to the bottom of the cycle. If you miss, keep the mouse over the box you’ve drawn and press the delete key. Try again. When you’ve got it right, read off the interval width in cents displayed beneath the box. (It may be shown only in cents (e.g. 86c) or as a number of semitones (each worth 100 cents) plus or minus a certain number of cents (e.g. 1-14c): in that case you’ll have to make the addition or subtraction yourself.) To assess vibrato width properly you need to measure more than one cycle. If you want an average then you’ll need to measure a great many, because as we’ve seen vibrato in players born after about 1875 varies according to musical context; but if you want to examine that variation then a smaller number of readings chosen from the contrasting passages that interest you will suffice.
¶71 Portamento can be measured using the same tools. Here we’re interested in the pitch space covered, how long it takes, what shape of curve it is, and how the loudness changes during it. Working out the properties of the curve is not a trivial task, and for most purposes may be overkill, 44 but spectrum displays can be very helpful in enabling one to understand how prominent portamenti seem to be when one listens. Anything smaller than about 0.03 secs is imperceptible so may as well be ignored except as evidence of finger technique, like the small slide up to the first violin note in this Sandler extract. The first real portamento (starting at 13.67 secs) is unmissable at about 0.2 secs long. It’s often impossible to be precise about the length of a portamento slide, and the slide that starts at around 19.2 secs shows why. The vibrato runs into and out of the slide: there’s no way to decide, without first conducting a programme of perceptual experiments, when the rising vibrato cycle at the end of the lower note stops and the slide begins, or when the slide ends and the new vibrato cycle on the upper note starts. 45 It is pointless to worry about these details at present. Spectrum displays make it all too easy to indulge in excessive precision which has no perceptual significance. But used sensibly they can teach us plenty about how devices like portamento work.
¶72 The same techniques could be used to study vibrato and portamento in singing and wind playing. Here, as also in violin playing, an important feature can be intensity vibrato, that’s to say, regularly fluctuating loudness as well as or instead of fluctuations in pitch. For listeners it’s often extremely hard to tell intensity from pitch vibrato, 46 and measuring intensity vibrato is a little more difficult because you have to take readings in decibels from several points (and the same points) in each of a representative sample of cycles. But it is common and needs to be taken into account. 47 An interesting but challenging example is Germaine Martinelli in Schubert’s ‘Die junge Nonne’, a song of which we’ll hear more in a moment (Sound File 6a (wav file)and Data File 9 (sv file)). Using the spectrogram display you can see here how her vibrato is louder at the extremes of each cycle than between them, and also just how irregular it is in pitch, especially when she is modelling the young nun’s fear (compare the somewhat more even ‘Hallelujas’ as the end). Switching in the wave-form display (tab 3 in Data File 9 (sv file)) 48 it becomes extremely easy to see the considerable extent of Martinelli’s intensity vibrato (look at 8.5 secs, for example); and the passage from 1.04 mins reveals how that extent tends to increase as she sings higher and louder, even though her pitch vibrato remains relatively steady.
¶73 Changes in loudness among the harmonics during vibrato produce changes in timbre or vocal colour. 49 We can study timbre vibrato quite easily using Sonic Visualiser. In Data File 9 (sv file) the layer tab with the little blue graph icon (probably tab 4, though SV sometimes reorders them) selects a spectrum analysis. This graphs the loudness of each frequency across the whole spectrum at the ‘now’ point (i.e. the central white bar), and as you drag the display across the bar you’ll see the graph change as the frequencies change their relative loudnesses. Using the note at 1’07” as an example, drag the display across the bar and you’ll see the heights of the loudest three or four frequencies (the highest blue steps) alternating as you move through the vibrato cycles. (There are other changes, clearest below the vocal fundamental, due to the continuing orchestral accompaniment.) You can find out which harmonics these are by selecting the ‘Measure’ tool (with the compass icon, at the right-hand end of the Tools toolbar above the display) and moving the mouse over the tips of the blue spectrum display. The orange full vertical line marks the fundamental and the short lines the overtones. You can do the same in the spectrogram layer if you wish. (Switch back to the ‘Navigate’ tool (the hand icon) before going back to the spectrum graph layer, however.)
¶74 You can produce a more easily readable display, albeit at the expense of obscuring almost everything else, by changing ‘Plot Type’ from ‘Steps’ to ‘Colours’. Move the display across the bar again, using the same note at 1’07”, and you’ll see the loudness of each harmonic indicated by bands of colour. It’s now very easy to see how, as each pitch/intensity cycle of the vibrato goes by, the colour (=loudness) of the fundamental and third harmonic alternate in relation to the second. If you want to see this change while the file plays, you first need to go back to the first tab, with the general settings for the session, and change ‘Follow Playback’ from ‘Page’ to ‘Scroll’. Now if you return to the combined spectrogram and spectrum analysis and press ‘Play’, you’ll see the spectrum analysis changing, mapping the changing timbre, while you follow the performance. You can use the speed control (bottom right dial, next to the volume control slider) to slow it down for a better chance to grasp what's going on.
¶75 Having looked at the changing timbre, now we need to use our ears. With the spectrogram layer on top, move ahead to approx. 1’41” and, using the ‘Select’ icon (the arrow), select 1’41.3” to 1’42.4”. Press the ‘Constrain playback’ and ‘Loop playback’ icons (immediately to the left of the S-shaped icon). Slow the playback speed to -580%. Bring up the waveform display so that you can see how the loudness varies regularly within each vibrato cycle. (It may help to increase the horizontal magnification, using the horizontal grey dial.) Now press ‘Play’. What you’re hearing, all being well, is a significant change of timbre from the top to the bottom of each vibrato wave. 50 Although the waveform is telling us that there’s a very large difference in loudness, the highest point of the vibrato wave much louder than the lowest, we don’t hear it that way: we hear the timbre changing. And if you switch in the spectrum layer set to ‘Steps’ you’ll see that confirmed: the loudest frequencies are more or less equally loud throughout the vibrato cycle, but their width changes. There’s a wider frequency band for each harmonic on the way down the vibrato curve and a narrower (more spiky) band on the way up, producing a ‘warmer’ (more consonant) sound on the way down and a ‘brighter’ (more focussed) sound on the way up. It’s a very clear example of a timbre vibrato. The measurable but hardly perceptible intensity vibrato is a simply by-product.
¶76 These effects appear to be, to some extent, dependent on text. With the spectrogram layer back on top, place the mouse over the vertical blue line that marks the left-hand selection boundary, and when the cursor becomes a double-ended arrow, click on it and move it leftwards, back to 1’39.3”. Your selection should now cover 1’39.3” to 1’42.4”. We now have two notes selected, both on the same pitch. The French text here is ‘[flé-]tri-e’, and so the vowel changes. 51 It’s the ‘e’ vowel that we’ve been listening to and that produced such a marked timbre vibrato, whereas the ‘i’ is much more confused, the loudness of the harmonics in constant irregular flux. We can see that with different vowels the harmonics interact quite differently, with consequences for timbre, at least in Martinelli’s voice, that go well beyond the simple fact of the vowel having different loudnesses for each harmonic. Using the tools provided by Sonic Visualiser we can make a useful start at analysing these kinds of details.
¶77 Pitch, loudness and timbre may all be cycling in vibrato, therefore, and in highly complex ways; and it seems probable that this causes the effect identified by Metfessel (1932) as ‘a halo of tone colouring’ or ‘sonance’, enriching the perceived tone of the perceived note. 52 To make matters yet more complex, Metfessel finds that the shape of the vibrato cycle differs between singers—a phenomenon I’ve not attempted to study here but that needs much more research. 53 All this suggests that vibrato is a far more complex phenomenon, with more ramifications for the effect of a performance on the listener (including the effects we perceive as expressive), than we have yet understood. There is a lot of very fascinating work to be done.
8.3. Sounds from speech, sounds from life
¶78 With singing there is inevitably much to be observed about the treatment of the text. Let’s begin by looking at signs of deep emotion in early 20th-century singing, and two in particular, the Italian sob and the German swoop. These seem to have much the same function and it’s not impossible that they are simply equivalents in two different stylistic languages. In an earlier article I wrote about Caruso’s sob, 54 and we can use SV to look at another example. (Sound File 38 (wav file) and Data File 10 (sv file).) This one comes from an irresistibly unlikely source, a 1930s recording by Max Meili of the late-medieval Italian lauda ‘Gloria in cielo’ issued on the L’Oiseau Lyre ‘Anthologie Sonore’ label. 55 The first of several sobs comes at 14.7 seconds—according to SV it lasts 0.13 secs—and a second, more spectacular, at 51 secs, lasting 0.22 secs. If you select it, without the sounds on either side, and if on the toolbar you click the ‘Constrain Playback’ and ‘Loop Playback’ buttons and the press ‘Play’ you’ll hear what it is. It’s a falsetto note approximately an octave above the destination pitch (a little lower in the first example, higher in the second) and—as you’d expect from falsetto—with only the lower harmonics sounding. It’s very quick and it curves up and then down, leading through an imperceptibly fast portamento into the main note. Its expressive effect relies on its similarity to an involuntary sob in a male: a sharp intake of breath reacting to sudden emotional stress forces air through the vocal chords without them having time to vibrate fully—hence the falsetto. It’s this effect that was such a regular feature of Italian male singing in the early 20th century and still lives on in the opera house in performances of 19th-century Italian opera. Why Meili thought it suitable in a lauda is anyone’s guess, but the text is ‘Gloria in cielo e pace in terra. Nat’è il nostro Salvatore’ (Glory in heaven and peace on earth: our saviour is born), so he’s inviting us to be deeply moved at the thought of the birth of Jesus. More curious still, he was Swiss, from Winterthur, and studied in Munich. But in any case there’s no doubt about what this sob means, nor about how it means it. Analysis of the sound provides a clear explanation for the effect we perceive. It’s an emotional signal applied to the start of a note whose text carries special significance, used at a point in the composition where it can be achieved relatively naturally.
¶79 Similarly the German swoop, which is much more common and obvious in female than in male singers, leads into a note, usually setting text with special emotional value, and at places where the composition allows it. So their function and placing are similar, even though national style and gender are not. Again, swoops can be so fast that one perceives them as emphasis of some sort rather than as slides up to a note, although that’s what they are. We’ve mentioned them already in discussing Lotte Lehmann’s style, where they are much used as signals of deeper feeling, and in Schwarzkopf where I suggested that they had, in a different and more detached expressive environment, become signals of irony. And most recently we saw striking examples in Gerhardt’s singing of ‘An die Musik’ where they clearly signalled strong feeling tied to descriptive words.
¶80 For a detailed example Let’s look at an extract from Lotte Lehmann’s 1941 recording of Schubert’s ‘Die junge Nonne’. (Sound File 39 (wav file) and Data File 11 (sv file)) 56 This is a transfer from a noisy original but one can still get a good enough spectrum display out of it to be useful. 57 A casual listen suggests that Lehmann is emphasising several of these notes, especially at ‘finster’ (dark), ‘Nacht’ (night) and ‘Grab’ (grave). It’s a Gothic-horror text in which the young nun of the title sings of the storminess of her previous life which she’s leaving behind for the peace of the convent and marriage to God. But Schubert’s music strongly suggests that her dark past is still very much with her, 58 so Lehmann is making the most of something that’s very clearly implied in the composition. A closer listen suggests that at least some of these notes are swooped up to from below, and that that is what gives them emphasis; and indeed if we look at the spectrogram we see that almost all are. The following table shows by roughly how much. (You get different results, incidentally, depending on how you set the Bins option: slides register as shorter the more precise the setting; for the readings below I’ve used Peak Bins.)
| Approx. length (secs) | 0.2 | 0.16 | 0.15 | 0 | 0.2 |
| Approx. interval | -9th | +6th | 4th | 0 | -3rd |
| Text | und | fin- | -ster | die | Nacht |
¶81 So these swoops at first get smaller and shorter. ‘Die’ (the) has none, since the word has no expressive content. But ‘Nacht’ (night) is stretched out, which compensates for the narrower distance and makes it more obvious than the rest. ‘Und’ (and), incidentally, is probably emphasised because it starts the phrase, and this whole phrase Lehmann intends to be intensely eerie. Another thing this example shows is that you can swoop up to repeated pitches, and singers often do so in order to give emphasis where the composition doesn’t help. Here the monotone has its own expressive value, which Lehmann aims to enhance. The next phrase repeats the first a semitone lower and shows a similar pattern of swoops.
| Approx. length (secs) | 0.2 | 0.16 | 0.17 | 0 | 0.2 |
| Approx. interval | +7th | -6th | +2nd | 0 | +2nd |
| Text | und | fin- | -ster | die | Nacht |
¶82 And then the chilling conclusion, with the swoops drawn out into a glissando up to ‘Grab’:
| Approx. length (secs) | 0.26 | 0.19 | 0.5 |
| Approx. interval | 5th | aug.4th | -6th |
| Text | wie | das | Grab |
¶83 What does all this signal? It’s possible that swoops make metaphorical connections with the same indrawn breath modelled by sobs, or some other index of shock and fear, providing what I’ve called the Gothic-horror element in this performance. An intermediate, or at any rate a very closely related source is to be found in speech. We compared examples of Lehmann reading and singing in chapter 4 (Sound Files 16 (wav file) and 17 (wav file)) and they illustrate a connection we can see again and again in expressive singing between song and speech. Expressive sounds from speech are taken into song, bringing with them the same expressive value. Or perhaps it’s not so much that song borrows from speech as that both draw on sounds with associations that may well pre-date speech, vocal responses of humans to deep emotion. 59
¶84 I’ve provided a lot of examples of speech-associated gestures in an article on ‘Expressive Gestures in Schubert Singing on Record’, using extracts from recordings of ‘Die junge Nonne’ and other Schubert songs from across the 20th century. 60 The following extracts are quoted here (slightly shortened and now with sound clips) because they provide a range of examples onto which we can add in order to start to assemble a list of types of analogue between musical performance gestures and sounds from life. In that article I showed a modern singer, Kathleen Battle, using the vocal signals of various states of mind to signal emotional states in Schubert songs , beginning with ‘Die Männer sind méchant’.
¶85 In the text, by Johann Seidl, a girl tells her mother that she was quite right to distrust her daughter’s lover; she has just seen him kissing someone else. She begins, ‘You told me so, Mother, He is a tearaway’ (‘Er ist ein Springinsfelt’.) (Sound File 40 (wav file)) 61 Knowing the text, it is fairly easy for most listeners to Battle’s recording to agree that this passage makes a general impression of disgust, an emotion that Gabrielsson and Juslin tell us has rarely appeared in empirical studies of musical emotion, perhaps because it needs more clues than just sound to identify it unambiguously. 62 Here the text and sound together leave little room for doubt. But what produces that effect? ‘Er’ starts loud and slightly sharp (suggesting a shrill manner of speech). ‘Er’ is connected by a portamento slur to ‘ist’, so ‘Er’ seems hissed by association (Errissst). ‘Ist’ is dead straight, the pitch sounds for less than a third of length of the beat, the rest is ‘sss’. The sharp ‘t’ of ‘ist’ is attached to ‘ein’ and gives ‘ein’ some bite, which it couldn’t otherwise have; and Battle also gives it a nasal tone and a very fast upper mordent (‘e/\in’). ‘Sh’ (of ‘Springinsfelt’) is all higher frequency and starts early, exploding into a loud ‘pring’ which starts straight, then slides in a continuous portamento down through ‘ins’ to ‘feld’. And there’s a hairpin crescendo-diminuendo through ‘insfeld’, giving a thrown-away end to the word that perhaps suggests dismissal.
¶86 These are all expressive gestures, evoking sounds from life. Some are onomatopoeic, the ‘isssst’ which we’ve learned to associate with hate and in particular, a threatening hate that could lead at any moment to violence. Then there are the sudden explosive consonants, ‘T-ein’ and ‘shPRing’, evoking the sound of sudden violence. And the rapid diminuendo at the end of a phrase that evokes a dismissive turning away.
¶87 Many kinds of gestures in song come direct from speech. The meaning of a sound gesture in speech is transferred to singing by converting the speech gesture into something with a more precise pitch and duration determined by the requirements of the musical context. Often the speech gesture invoked is determined by the text, but by no means always. There’s an example in Battle’s recording of Schubert’s ‘Rastlose Liebe’ (Sound File 41 (wav file)) 63 where she sings ‘Ohne Rast und Ruh’ (without peace or rest). In Battle’s wildly restless performance ‘ohne’ is the word given the largest gesture in the phrase, not because it is the most important word but because Schubert’s setting puts it in the most expressive place, and the singer can get the strongest effect by working with that. This emphasises that gestures borrowed from speech don’t necessarily have to arise from the text in order to work; their expressive content in speech may be taken over and applied in music, either because their emotional content works effectively in a musical context or simply because the sound seems right. (Clearly this has implications for our understanding of expressivity in instrumental music, to which I shall return below.)
¶88 What about the general character of Battle’s voice in this performance? This is not how Battle normally sounds in Lieder. A more typical extract, which conveniently includes both her lyrical and her characteristic clipped styles would be ‘Lachen und Weinen’. (Sound File 42 (wav file).) 64 So what’s different about ‘Rastlose Liebe’? In ‘Rastlose Liebe’ Battle doesn’t just make ‘Ohne Rast’ a continuous portamento—we can hear that—she also changes her vibrato, speeding it up by around 10% from her usual rate (which is very roughly 135ms per cycle as opposed to 150 here) and reducing its width by around 30%. The effect is that she sounds terrified. This is a neat example because it shows so clearly how effects that we all recognise immediately as signs of terror—racing heart, tremor in one’s voice—can be reproduced analogously, indeed almost literally, in singing, and they inevitably cause us to share [or at least to recognise—more about this distinction below] some of the feelings that would normally evoke them. There’s lots of research along these lines. The motor theory of speech perception, 65 Juslin’s functionalist perspective, 66 Sloboda’s dynamic awareness , 67 Cox’s mimetic hypothesis, 68 Watt & Ash’s hypothesis that the action of music is to mimic a person, 69 and indeed, Peter Kivy’s contour theory, 70 further developed by Stephen Davies: 71 are all describing this phenomenon, and it seems evident that this is a fundamental key to understanding musical communication. We read sounds through what our bodies would do to make them. The truth of that is particularly clear in this example, because the causes and effects are so obvious and easy to identify. But the same process is likely to be working in much less obvious cases as well.
¶89 My next few examples all come from Schubert’s ‘Die junge Nonne’, whose psychological portrait of a disturbed young woman offers us the chance to study the vocal representation of fear in more detail.
|
|
¶90 Meta Seinemeyer, in a recording from 1928 (Sound File 43 (wav file)), 72 contrasts the opening phrases, in which key words (Wipfel, Balken, Donner) are hit hard through initial consonants sung at full amplitude, with the softer-edged ‘Und finster die Nacht’, whose sounds crescendo up to their full strength (which is less than for the hard notes). She also slows down for them, but that’s less crucial. The speech analogy is obvious: spitting-out sounds evoke anger in speech and by analogy the fury of the storm; crescendoing sounds evoke something more complex, since there are a number of situations in which we might crescendo through a sound in speech. Mystery tinged with fear might be one, and is perhaps what is evoked here. But one can also think of the contrast between hitting and stroking or pushing. Thinking visually one would call on hard edges contrasted with blurred. All these are obvious equivalents using different senses, equating to the perception of this passage of sound. To pin a precise meaning onto these sounds at ‘finster die Nacht’ would be silly, because it would be to attempt to make precise something that is by its very nature not precise. That is the point of the gesture, that it evokes unease, which by definition cannot be precisely explained: its precise meaning is imprecision. But my methodological point is that once one understands what’s going on in the sound it’s not hard to see what it means.
¶91 Kathleen Battle in the same passage offers us several details that suggest fear through loss of control. In ‘zittert das Haus’ (Sound File 44 (wav file)) 73 Battle sings ‘das’ on a different note entirely from Schubert’s, and not a scale note: it’s 650Hz instead of 550 (c''#), about a tone and a quarter above pitch. Then at ‘finster die Nacht’ (Sound File 45 (wav file)) 74 the slides up to ‘finster’ and ‘Nacht’ are obvious enough to the ear; a little more subtle—and this is another case where a visual display can help—is the shallow but longish slide up to ‘wie’ and ‘Grab’, and the combination of that on ‘Grab’ with increasing vibrato and crescendo/diminuendo. These are not characteristic of Battle’s normal style: in fact she’s extraordinary among female singers of her generation for her ability to start a note with all the amplitude and vibrato it’s ever going to have, and for keeping them both absolutely regular throughout a note; it’s an exceptionally regular voice, and so these small changes have much more significance for her than they would in others’ performances. One has to read gestures in relation to their local context, in other words, not off some kind of translation table that attaches specific meanings to specific sounds (heaven forbid). Just as interesting is ‘das’ which becomes something more like ‘dash’ as she moves her tongue back from the ‘s’ position to ‘sh’ so that not only are the vowels the same, ‘das Grab’, but so are the consonant positions for ‘sh’ and ‘gr’. An unnatural but eerie frozen effect is produced by unnatural ‘s’ sound and the unchanging mouth positions, as if the body were frozen into immobility with terror.
8.4. Music can model...
¶92 We’ve seen here a number of different types of reference from musical sounds to sounds from life. In ‘Die Männer sind méchant’ we heard the voice copying the sounds of anger, that is to say making in singing the same kinds of noises one would make in speech, the most direct translation possible from one to the other. In the hissing we heard sounds that signal imminent violence, reminding us perhaps of sounds of anger in animals (geese, snakes) used also by humans as a conventional signal for dislike. In ‘Rastlöse Liebe’ and in ‘Die junge Nonne’ we heard the voice taking on the effects of fear on the human voice; knowing how that feels ourselves we recognise what is being signalled. In Seinemeyer’s performance we heard notes attacked with sound shapes that depict behaviour (violence in the storm) and images linked to emotion (the darkness of the night). These are all different kinds of reference, but all things that musical sounds are able to model.
¶93 As a way of understanding this let’s make a hypothesis and then test it with further examples. Music is able to depict anything that changes shape over time. According to this hypothesis music ought to be able to model emotions, and therefore to refer to anything that generates an emotional response, because feelings involve a sensation, caused by chemical processes in the brain, that may hit us hard (an onrush) or grow more slowly, that may overwhelm us or simply make us feel uneasy, and that may disappear quite suddenly or very gradually; in other words there are a great many shapes that emotional experiences can have, and they are made over time, so music models them very well. 75 Similarly music ought to be able to model motion in space, for example human or animal locomotion, especially if has some irregularity in it so that it’s not so even as to be characterless. Music ought to be able to model processes in the natural world that involve distinct shape and motion, storms, earthquakes, streams, leaves in the breeze, the sea. It ought to be able to model anything that involves sound, obviously, including the voice, habits of speech and any kind of vocal signal. It ought to have the greatest difficulty, if it can do it at all, in modelling anything that is unchanging, for example a road, a house, and static features of the natural world including the landscape: it’s interesting to see composers and performers trying to get around that by modelling instead characteristics of people that seem landscape like; for example mountains become nobility which becomes large slow-moving sounds. 76 But on the whole this hypothesis seems on the face of it to be plausible. To test it a little let’s look at some more examples from singing.
¶94 Susan Metcalfe-Casals’s recording of ‘Die junge Nonne’ (Sound File 46) (wav file) 77 includes unusually short and hard-hit notes for ‘Blitz’ (lightning), which models its speed, suddenness and brightness (vision and motion). Her enormous swoops up to ‘Grab’ perhaps evoke vocal sounds of emotional shock (spontaneous emotional expressions). Her sudden softening and diminuendo on ‘Heiland’ (saviour) is a cultural reference (we’ve learned about God) drawing on speech expressions of awe and love (modelling emotion), as is her narrowing of spectrum and of vibrato to make a choir voice for ‘Alleluia’. Her curious singing of ‘Und finster’ as ‘Und-er finster’ seems to broaden and darken her voice, metaphorically mapping darkness between the spectra of sound and vision. Is this a shape changing over time, though, or is it a connection that the brain can make for other reasons? I don’t understand this particular example well enough to be sure, but I think we must in any case allow in our hypothesis for the brain’s ability to recognise similarities across domains, and especially between sound and vision. The notions of dark and bright seem to map very easily between sound (dark = low harmonics, bright = high) to vision (low intensity and high intensity light), and this seems to have nothing much to do with motion over time, other than at an immensely fast level of which we could never be aware.
¶95 So let’s expand our hypothesis. Music is able to depict anything that changes shape over time, or that is perceived through sensations of relative distance, height or brightness. This would include music’s evident ability to model vertical position in space through pitch height, distance via loudness, and anything that is characterised particularly by its reflection of light (shining swords, dark nights). This is still a cautious hypothesis. A recent study by Zohar Eitan and Renee Timmers, 78 showed that although different cultures express what in the West we think of as pitch ‘height’ in many different ways, including ‘size, brightness, angularity, mood, age, and social status’, subjects nevertheless had no difficulty in deciding correctly which indicated (in western terms) ‘high’ and ‘low’. Music, then, can probably suggest all these characteristics, and no doubt others, clearly enough that the signal is not significantly distorted by cultural assumptions.
¶96 Without a doubt the most extraordinary recording of ‘Die junge Nonne’ is Lula Mysz-Gmeiner’s from 1928 (Sound File 47) (wav file). 79 Uniquely among the 78rpm recordings it is spread over two sides because it is much slower than any other. Among its evocative expressive gestures is a drawn-out transition between ‘das’ and ‘Grab’ almost identical to Battle’s, and a plain uninflected ‘Grab’ that suggests the deadness of the grave, a translation of lifeless immobility from vision to sound and incidentally an effect that Elly Ameling also chooses half a century later. What this adds up to is a reading of this song quite different from any other. For the others the narrative is to be read literally: the girl joins a convent and becomes a metaphorical bride of Christ. For Mysz-Gmeiner this is all metaphor. What the girl leaves behind is not just her past life but life itself; she longs only to meet Christ through death. The ritardandos and diminuendos which shape so many words are the effort of a dying girl to speak at all; ‘so tobt' es auch jüngst noch in mir’ (so also [a storm raged] not long since in me) uses the narrow pitch band and falling cadence we use in speech for wistful regret; the trembling monotone at ‘und finster die Brust wie das Grab’ (and my heart is dark as the grave) brings to those words her fear of death (death in the monotone, fear in the trembling). The ‘Alleluja’s, where the music almost stops entirely, are her last words. This is fascinating as a compendium of evocations of death in singing, but still more so for its demonstration of just how much the meaning of a composition can be transformed by a performance, through the signification of the expressive gestures that the performer deploys.
¶97 Once again we can make our hypothesis more explicit by saying that music is able to depict anything that typically causes a change in the sounds we make. This includes mental and physical states that change the sound of our voice, such as illness, excitement, depression, love, joy, dislike, fear, questioning or enticing another, and so on. The range is as vast as our powers of vocal expression.
¶98 As an example of a single performance moving through a sequence of images vividly evoked a striking example is Dietrich Fischer-Dieskau ’s 1951 recording of ‘Das Fischermädchen’. 80 As one of the lightest of Schubert’s last songs it may not seem a promising candidate, but Fischer-Dieskau, as was suggested in chapter 4, has an exceptional ability to generate evocative gestures in sound, and since we’ve considered his voice and his influence in some detail there it seems worth looking closely at one example where we can see his mastery of subtle changes of sound and mood from word to word. I’ve arranged the most striking gestures in a table and invite readers to listen to the song reading the table. The complete text first:
|
|
¶99 Now play Sound File 48 (wav file) 81 against the following table of vocal effects:
| Du schönes Fischermädchen, | You beautiful fishermaiden, | |
| schönes | cresc-dim, vibrato increase | surge of tender feeling |
| Treibe den Kahn ans Land ; | Pull your boat toward shore; | |
| ans Land | cresc, slowing vibrato | welcoming? |
| Komm zu mir und setze dich nieder , | Come to me and sit down, | |
| zu mir | cresc-dim | personal engagement |
| dich nieder | ‘nieder’ slightly louder | unthreatening personal engagement |
| Wir kosen Hand in Hand . | We will speak of love, hand in hand. | |
| Hand in Hand, 1st time | large crescendo | emotional frisson |
| Hand in Hand, 2nd time | diminuendo | simple non-threatening |
| Leg an mein Herz dein Köpfchen | Lay your little head on my heart, | |
| an mein Herz | cresc-dim, portamento on ‘Herz’ | deeply felt |
| Köpfchen | pitch inflection on ‘-chen’ | affectionate/parental |
| Und fürchte dich nicht zu sehr ; | And do not be too frightened; | |
| fürchte dich nicht | shortened, small pitch inflections | playful |
| zu sehr | cresc and swoop | ironic, patronising |
| Vertraust du dich doch sorglos | Indeed, you trust yourself fearlessly | |
| Vertraust...Meer | louder, strong upper harmonics | light manly, fearless |
| dich | cresc | speech emphasis |
| sorglos | loud and steady | brave |
| Täglich dem wilden Meer. Mein Herz gleicht ganz dem Meere , | Daily to the wild sea! My heart is just like the sea, | |
| Mein Herz...Flut | stronger lower harmonics | warm, intimate, personal |
| Meere | dim, portamento | fluctuating |
| Hat Sturm und Ebb' und Flut, | Having storms and ebb and flow, | |
| Sturm | pitch wobble | disturbed |
| Und manche schöne Perle | And many beautiful pearls | |
| und manche...Perle | more evenly balance harmonics | lighter, brighter |
| schöne, 2nd time | cresc, pitch slide on ‘schö’ | emotion |
| Perle, 2nd time | regular vibrato, steady loudness and pitch | purity |
| In seiner Tiefe ruht . | Rest in its depths. | |
| ruht, last time | slower, portamento | seductive |
¶100 The evoked emotions suggested in the third column may be hopelessly over-simplified or over-interpreted, 82 but the effects in the middle column are not and they show just how much of Fischer-Dieskau’s attention is given to responding to any words with expressive potential in the text. As Walter Legge realised when accusing Fischer-Dieskau of singing through speech, 83 these gestures are very largely drawing on speech inflections, and that has to be seen as a consistent feature of his personal style. It’s not surprising, of course, that singers should be so concerned to bring expressivity from speech into singing. Speech allows much more expression than singing does, constrained as singing is by the written pitches and durations; and the amount of brain activity required when one listens closely to music in order to decode sounds shaped in so many dimensions inevitably means that less attention can be paid to the meaning of words when they are set to music than when they are read. Speech-led expressive gestures bring some of that meaning back into the music and intensify our perceptions of the interaction of words and notes in the composer’s setting. It’s relevant, too, that speech and music appear to be linked in the brain, to the extent that subjects have difficulty remembering the words of a song without singing the tune, and find it surprisingly hard to recognise the identity of a tune when the words have been changed; 84 while victims of strokes and other kinds of brain damage who’ve lost areas of the brain essential for speech are nevertheless able sing words they can no longer say. 85
¶101 One could multiply examples indefinitely, though one might be hard put to find so many in a performance by any other singer. But I think these are enough to suggest just how much music can model by being able to model almost anything that changes over time. Motional and emotional states are encoded analogically in numerous details of the sounds that the performer is making. Singers, and at a more abstract level instrumentalists, use these sounds as ‘signs of emotive actions we recognise from daily life. This isn’t a separate musical sign-language, in other words, but rather uses the mind’s naturally selected ability to connect phenomena through common features. It’s a survival skill that’s become a way of understanding the world. The performer integrates the music with our emotional lives. And that’s surely one of the most important things that performers do, and one of the absolutely essential ways in which music works.’ 86 Expressive performance happens to a large extent on the level we’ve been examining here, where changes are measured in tenths of a second or less: these are the expressive signals we perceive, with more or less awareness depending on how closely we choose to listen, and with more or less change to our core affect depending on how closely we allow ourselves to become involved.
¶102 Research into emotional contagion has much to teach us about this latter process. Hatfield, Cacioppo & Rapson argue on the basis of empirical studies that individuals vary both in their ability to ‘infect others with emotion’ and their susceptibility to emotional contagion, that’s to say, the ease with which emotional expressions by others modify their own state of mind. 87 There is every reason to suppose this true also of musical performers and listeners. It’s quite likely, therefore, that many of my interpretations of Fischer-Dieskau’s sounds in ‘Das Fischermädchen’, and indeed elsewhere in this book, seem more or less wrong to you. It would be unwise to expect agreement on the emotional effects of music. Indeed, I’ve argued here that it’s our ability to feel quite differently about it that gives it much of its social power. At this stage of research, then, all we can sensibly aim to achieve is to agree on some general principles and test them on a lot of specific cases.
8.5. Expressivity and signification in instrumental music
¶103 It seems inevitable that these kinds of processes contribute to the kinds of musical gestures that composers use. Indeed, rather than see performance gestures as arising out of the requirements of compositional gestures, I’d be more inclined to suggest that composition gestures are performance gestures formalised into pitches and durations; and both have their origins, I suggest, in the ‘emotional shapes’ which underlie so many of the gestures we’ve been examining. 88 The progression from consonance to dissonance to consonance, in its process of intensification-relaxation, works in the same way as a crescendo-decrescendo or a lengthening-shortening or a vibrato widening-narrowing or pitch raising-lowering, except that in all the performance gestures the process can be inverted and work just as powerfully if other signals are coherent with that. So, for example, reducing vibrato for a moment can produce at least as much intensity as increasing it, or getting quieter as much intensity as getting louder. It depends on what else is happening and why, which emphasises both that these signals are always parts of larger collections of signs, not necessarily pointing all in one direction, and also that performance gestures are more flexible, easier to programme with different meanings in context, than are compositional gestures whose meanings tend to be more stable. But all these turn into sound the sense of increasing followed by decreasing intensity which characterises almost all emotional experiences.
¶104 It’s clear that through this common reference expressive performance gestures and compositional gestures, signs (whether indexical, iconic or symbolic) and topics, are closely related. Can we therefore consider them all as functions within a broader musical semiology? Almost certainly we can, and most of the analyses presented here could be incorporated into a semiotics of performance, but I don’t intend to do that here, and am happy to leave others with more investment in semiotic theory to do so. I’ve tried throughout this book to avoid attaching my observations to theory simply because I think it’s too soon to direct this rather new subject towards any existing theoretical model. Better for now to make more observations of practice with a view to deriving theory from it, than to begin from theoretical approaches designed to deal with compositions and to squeeze performance practices into their necessarily narrowed channels of thought. We need to be able to acknowledge and work with the unfixedness of performance, and we can’t do that with models designed to explain the much more formalised procedures of composition. It’s also arguable, and I think in due course may be increasingly argued, that empirical investigations of perception and cognition undercut theory, so that for example cultural theory may be seen as simply a verbal reification of cross-domain mapping in the context of a process of Darwinian cultural evolution, and semiotics an abstraction from it. But many may disagree, and in any case the subject will go where it’s taken.
¶105 I do think, though, that what we’ve seen in this chapter may suggest that musical semiotics, in leaving aside performance, has to date been unduly narrowly focussed. In putting behind us two centuries of writers on musical meaning—including such figures as CPE Bach, Rousseau, and indeed the much-derided Deryck Cooke, all of whom at least assumed performance as integral to the realisation of affect—we are, of course, obeying the demands of a theory-led musicological culture, itself led by more general scientific-positivist preferences, apparently replacing naive emotional response to musical signification with a more distanced view of what musical gestures might signal in a more abstract way. In a score-based culture intensified by decades of score-based analysis it seems much more natural than it would have in the 18th, 19th or early 20th centuries to see musical signification as a matter of patterns symbolising various kinds of order within a functional linguistic system, a structured process which through its coherence and logic gives satisfaction to the mind. But bringing performance into the equation disrupts this tidy intellectual world. It’s evident to anyone who listens to music with any kind of engagement that it is not just a symbolic system that stimulates the intellect: it also, as people have always recognised, engages with our emotions. And when we listen to performers, and especially to singers, it’s quite obvious that the kinds of things they are doing have a direct physical relationship to the kinds of things our bodies do when they are emotionally engaged. It’s the sounding gesture, not the written one alone (to conceive of which one has to assume score-reading without imagined performance), that calls the emotional sub-routine, but call it it does, and we need to find a way of talking about it once again.
¶106 We are now in a good position, I hope, to address from the perspective of recorded performance a notoriously hoary issue, namely the kinds of meanings to which performance gives rise in instrumental music. I suggested at the end of chapter 5 that performance style in instrumental playing has changed less than singing because of the necessarily narrower range of possibilities allowed by an artificial instrument, and I implied also that this was unproblematic in the sense that not having text to set removed much of the compulsion to illustrate particular notes or progressions with widely varying expressive gestures. It is absolutely the case, therefore, as commentators have long supposed, that the performance of instrumental music is more single-mindedly focussed on pointing up the musical structure than is song. Nevertheless, the starting point for any consideration of expressive gestures in instrumental performance has to be this observation, that the treatments of the sound that cause moments in instrumental playing to seem expressive are exactly the same kinds of treatments that singers use in texted music. As I’ve just suggested, a sudden crescendo still models a surge of emotion, deepening vibrato greater intensity of feeling, and so on. The languages of signification are the same and it would be absurd to suppose that wholly different mental systems are used when we respond to acoustically related gestures in singing and in playing. Although instrumentalists are not using speech directly it’s perfectly possible that they invoke speech gestures as well on occasion. Indeed, we shall see one in a moment when we look at Alfred Cortot playing ‘Der Dichter spricht’. So we need to see instrumentalists and singers and listeners all bound up within the same expressive and interpretative world, ‘speaking’, as it were, the same language, many of whose words are more innate than learned. 89
¶107 It follows, that most of what has been said about the workings of expressive gesture in singing is relevant also to playing. That is not to say that we should treat playing as if it were singing. It would be ridiculous to try to attach specific meanings to instrumental gestures by reading across from singing, not just because it misses the whole point of instrumental music as an abstraction from singing, 90 but also because the unfixedness of performance gesture is at its most effective and fascinating in the absence of text. There may be exceptions, most obviously in instrumental arrangements of songs, when performers may well imagine and respond to the words as they play, especially if those words are well-known. Heifetz’s recording of the Schubert-Wilhelmj ‘Ave Maria’, which we looked at earlier in this chapter, may be such a case. (Sound File 49 (wav file) has the complete recording.) 91 The following table suggests how some of Heifetz’s gestures may relate to his sense of the words. (Sounds emphasised by Heifetz are marked in the text in italics, with a joining underline for the portamenti in the penultimate line.)
|
|
|
|
|
|
¶108 I can see no convincing indication of Heifetz treating his second (his last) stanza as a representation of either of the remaining stanzas of text. 92 Wilhelmj’s double-stopping in octaves and then in sixths, as realised by Heifetz, 93 seems a wholly musical decision aimed at increasing intensity towards the end, which only goes to emphasise that that is what most expressivity in instrumental playing is for, to respond to dramatic possibilities inherent in the score and in the occasion of its performance.
¶109 Another exception, and rather a large one, concerns accompaniments to song and aria. Clearly in these cases there are very good reasons why instrumentalists may choose expressive gestures in the light of specific images. And of course the same goes for all kinds of programmatic music. The sword motif in Die Walküre, to take but one obvious example, would be less effective if played without the trumpeter aiming for the brightest possible sound (strong upper harmonics = bright = glinting = sword). But that same sound can bring a perceptually significant edge to a trumpet note in an apparently abstract musical context, and the metaphor will still work, not quite all the way to ‘sword’ but far enough to lend that moment a sense of brilliance as the note ‘cuts through’ the orchestral texture. All this is obvious and needs no further comment. It simply confirms that the sound modifications used when thinking beyond music are of the same types as those that respond only to musical structure. Shaped change in sound is itself enough to do expressive work, identifiable metaphorical mappings bring added associations, text pins those down, but neither text nor identifiable metaphor are necessary for expressivity: change in sound, or in relation to expectation, 94 is all that’s required. Change works, though, because it represents other kinds of change, the result (as we’ve seen) of selection for extreme sensitivity to sound change. Even the most restrained expressive performance affects us because even a small change in the profile of a sound is sufficient to attract our notice and trigger a search for meaning.
¶110 It follows from the identity of texted and untexted expressive gestures that listeners can with the greatest ease map across domains from shaped sound to many other kinds of shaped experience. And it shouldn’t surprise musicians in the least that a great many listeners do generate images or narratives as they listen to performances of apparently abstract music. This is a practice that musical training in recent times has tried hard to eradicate. There’s a strong sense among music educators that musical experiences arising from appreciation of the functioning of musical structures are more powerful and in some way more proper than experiences arising from cross-domain mapping to imaginary stories or scenes. But how can that be known? If brains do it so easily is it necessarily distracting rather than enhancing? It seems distinctly possible that academic music has been excluding on principle a large area of sensation. At any rate it needs rethinking, preferably in the light of new research in music cognition that explores these kinds of experiences in a great many subjects. Gabrielsson’s work on ‘strong experiences of music’ has made a very important start. 95 It shows as clearly as anything that experiences of music associated with very specific memories and imagined scenes can be overwhelmingly powerful for a great many people. 96 Musicians need to look at this whole issue with more care and more respect.
¶111 Linked to these issues are the effects of music on clients and patients with physical and mental impairments. Music therapy is a particularly interesting case for us because of the way in which appropriately shaped performance is improvised in order to interact communicatively with the moods and gestures of clients, enabling communication through sound with a specificity and intensity that cannot be achieved at first through language. 97 Similarly, Alzheimer’s patients played to in a style appropriate to their changing states, can recover, for as long as the music lasts and for a little time afterwards, faculties that in every other situation they appear to have lost: memories of songs and tunes, coordination as they sway and clap in time to the music, concentration, focussing together on the music, participation, singing and moving together. 98 Instrumental music can achieve far more, then, than simply to stimulate intellectually sophisticated audiences of musical cognoscenti. But it does it with precisely the effects that we’ve been looking at throughout this book. Clearly there is a great deal about the power of absolute music that we’ve not been studying as musicologists but that is immediately relevant to how music works in us. It would be good to see the study of performance moving into those areas in the years to come.
¶112 So in assuming that expressivity in music doesn’t have to represent anything at all, we need to be careful. We may as expert listeners choose to focus our attention on the relationship between expressive gesture and musical structure, but that’s not to say that even our educated minds are not also finding references to extra-musical domains. It may only be our attention to the structure that is masking the results. We certainly do not ignore them nearly as much as we think. It’s perfectly obvious, for example, that there is happy music, triumphant music, solemn music, sad music, and so on, and these analogies are not ignored by any of us. (Imagine hearing the opening of the finale of Beethoven’s 9th symphony without being aware of a crisis, or the finale of the sixth Brandenburg without a sense of speed (however slowly it’s played).)
¶113 We need to be cautious, therefore, about assuming that apparently abstract performances, making only the most restrained use of flexibility in tempo, loudness or pitch, make no call on metaphorical association. In an important sense, as we’ve seen, change in sound is itself metaphorical of change in feeling. And this is almost certainly the reason why performance may be relatively ‘straight’ and still very successful. Think of pianists from the 50s through the 80s, figures such as Curzon, Kempff, Brendel and Ashkenazy. Here the implications of the ‘musical argument’ are being realised and pointed-up far more than they are being expressed emotionally: these pianists are (to borrow the options outlined in chapter 2) ‘Making audible aspects of the music’s structure’ much more than ‘Giving it emotional force through expressivity’. The means, however, are essentially the same as in earlier more expressive performances and as in vocal performances, raising the possibility that their ultimate (evolutionary) origin may be in vocal expression of emotional states. Even pointing up musical structure is not emotionally neutral, as the intensely favourable response to these pianists shows very well.
¶114 To see metaphor at work in instrumental performance it will, once again, be most helpful to take a rather gross example to begin with. Film survives of Cortot demonstrating ‘Der Dichter spricht’ from Schumann’s Kinderscenen in a masterclass in Paris in 1953. 99
-

- Figure 20: Alfred Cortot, Schumann, 'Der Dichter spricht' (Kinderscenen), with spoken commentary (1953)
¶115 In Figure 20 Cortot shows the student pianist how he imagines a narrative as he plays, one in which the poet makes a statement, repeats it, and then (bars 9-12) asks a question. How is the question asked in sound? Evidently Schumann has done much of the work already, writing a line with an upward inflection and an unstable harmony at the end. But the player has to do something too. With questions in speech, the crucial moment is that final upward inflection. If it’s long, which is what Schumann has notated, it’s a meditative question, rhetorical, not expecting an immediate answer. To make the second question tender, as Cortot suggests, one lets the sounds overlap, running them into each other as in tender speech. Alternatively, if one were to shorten the final inflection it would become a interrogative: the sense of incompleteness that a cut-off final sound gives is an essential ingredient in a question that expects an answer. A little bit long is how Schumann has marked it, so if it’s a question at all for him then it may be rhetorical or there may be some uncertainty. But that’s a historical matter, not an interpretative one. If we decide to make it an interrogative we easily can. Either way, we can then think of the recitative (bar 12) as a process of thought, as the poet considers his answer. And if we want to, we can use the high G as the moment when his answer becomes fully formed, and the preceding polyphonic passage as the forming process. In that case, the G needs to be striking, which can be done by making it longer and also by lifting the pedal so that the sound clears just as the poet’s mind clears. Sanctioned by neither Schumann nor Cortot, this is nonetheless a clear example of the way we call on sounds from life, and on analogies, in order to understand what music means. And it shows, too, how an instrumentalist can direct that meaning.
¶116 With Cortot, or with performances in that highly expressive tradition, it’s relatively easy to spot these references. And so listening to him is a relatively lifelike experience. The music seems to be about more than just sounds because it is. In later 20th-century performance practices it’s lifelike to a much lesser extent, and focuses much more on structural exegesis. One hears a musical argument more than an emotional one, but as I’ve explained, that is not to say that no emotional work is being done. On the contrary, it seems likely that listeners adjust their expectations to the scale of the performer’s expressive gestures and respond to smaller gestures with appropriate intensity.
¶117 Artur Schnabel’s 1947 recording of Schumann’s ‘Träumerei’ from Kinderscenen provides a good early example (Sound File 50 (wav file)), 100 and one we can compare with Cortot (Sound File 51 (wav file)). 101 Cortot changes speed with bewildering unpredictability, no doubt modelling the unpredictability of dreaming (the title). In so far as his performance is structured by the composition it’s by the melodic lines and fragments he emphasises as they pass by. Schnabel, on the other hand, plays relatively regularly, with much less rubato—the placing of notes is never surprising—and much more even dynamics. His performance seems to be shaped by the harmonic weight of each chord and by the voice-leading that creates it. It’s the music rather than the title that drives the performance. Within this even flow the changes are smaller but for their size are more significant than in Cortot. The loudest events in the first phrase are the chords on the second and fourth beats of bar 3 and the second of bar 4, in other words the chords that set up and enact the phrase-end cadence. Nothing is as loud again (though the repeat of those moments comes close) until the harmonic turn through c-minor and D-major sonorities in bar 10 which generates much of the second half of the piece. Consistently, Schnabel heads for the harmonic cruxes, both through loudness and rubato. But the changes that create these moments of focus are smaller than in Cortot’s or than they would have been in other earlier performance styles. In other words we are seeing a new interest in regularity, and also in compositional structure as the chief factor placing emphasis in the sound. For the listener this requires more attention because the performer is no longer reaching out to grab one’s attention through surprise.
¶118 This Cortot example is extreme, of course, because it’s modelling something already curious, but it’s just a particularly clear example of the way in which so much early recorded music-making, especially from the 1920s and 30s, engages the listener through unpredictability and the inability of the brain to find anything repetitive that it can cease to attend to. New information is constantly flowing in and demanding new analysis. Schnabel’s approach to the listener is different, and heralds a new approach to performance in general. Because much on the surface is regular there is less new information about timing and loudness to be assimilated and to have a cause assigned by hearing’s naturally selected responses. If one wants to be moved by the performance one has to listen more purposefully, engaging cognitive processes that will compare what is heard with what is known about musical structures and processes. Otherwise one has simply to let the pretty sounds wash over one and drift away.
¶119 One can see similar tends in singing. Compare for example Janet Baker and Lotte Lehmann singing Schumann’s Frauenliebe und Leben. 102 For one the lover/wife/widow is an open book, naïve, passionate and desolate; for the other she is more private, exploring her feelings discreetly within herself. For one the score is a starting-point for the recreation of life; for the other a map of a musical work, specifying a journey from which deviation is out of the question. Vibrato, just as for string players, now does the much of the work of emotional expression. Pianists continue to work with loudness and timing, but on a much reduced scale. And so on. This is a very different expressive world from that of pre-war performance. Thus in Schnabel, and then the new generation dominating the scene in the 1950s, 60s and 70s, what we’re dealing with for practical purposes is a grammar of expressivity of structure that, however it may actually be affecting us through our naturally selected and culturally learned responses to music, we recognise consciously first of all, if we have the training, in relation to musical structure and not primarily as representative of anything else.
¶120 Perhaps this helps to explain why music analysis arose at the same time that instrumental music came to be considered the highest form of musical work, reaching the apex of its intellectual popularity at the time (the 1970s) of least performance expressivity. Performance and structure are closer in these kinds of performances, more completely (though never fully) mapped onto each other, so that performance doesn’t ‘interfere with’ or ‘distract from’ the understanding of structure. Such a view became endemic to musical academia and still is. It was partly this rather strict musicological approach in performance, together with frustration at its lack of historical intelligence, and surely also sheer boredom at is continuingly predictable results, that fired the HIP movement.
¶121 A final topic that should concern us, in the light of this discussion of what expressivity in music is for, is the larger question of music’s evolutionary purpose. 103 This is not just a (pre)historical question. We’ve seen how naturally selected responses to sound still underlie our responses to western art music, overlaid with and shaping millennia of cultural evolution, because the neural circuits that evolved for this purpose are still present and are still processing incoming sound. We must suppose, therefore, that whatever it was that musical ability evolved to enable us to do still plays some part in our response to music of all sorts. This is an area of intense research at the moment (almost all of it outside musicology), and a survey of the literature would require a book in itself. To conclude my discussion of expressive performance I want to focus attention on just one theme. (Another, runaway sexual selection for acoustic displays, has been discussed already.) 104
¶122 James Russell, in an article on the psychological construction of emotion, distinguishes between ‘core affect’ and ‘full-blown emotion’. 105 Core affect is ‘a neurophysiological state that is consciously accessible as a simple, nonreflective feeling that is an integral blend of hedonic (pleasure-displeasure) and arousal (sleepy-activated) values.’[147] Less formally, core affect is a feeling, ‘an assessment of one’s current condition’, in effect a mood.[148] It is pre-cognitive and lacks as yet any attribution to a cause: attribution comes through reflection as one searches for reasons underlying a feeling. ‘Muscle tension and autonomic nervous system changes may, however, be direct consequences of core affect.’[156] What Russell is describing seems to be the state, and its consequences, that we experience through unreflective listening to music. Music generates core affect and that causes physiological and psychological changes in listeners. An identifiable cause—a narrative such as one finds in a song text or such as one may invent—is not necessary to generate the feeling, although it may explain it on subsequent (immediate or later) reflection. Such reflection, relating the core affect to its apparent causes and to their implications for one, might generate a full-blown emotion, but in music, and especially in instrumental performance, that is by no means inevitable. On the contrary, for Russell the evolutionary value of core affect is precisely that it does not automatically generate full-blown emotion, but rather allows the possibility that by responding to seeing emotional states operating on others, in life or (in modern times) in film, or (we might add) in music, and in having one’s core affect changed by that response (through empathy), one is able to learn safely and without real, undesirable consequences how situations feel.
¶123 This brings us very close indeed to an essential aspect of one of the leading current theories of music’s evolutionary value. Most fully worked out by Ian Cross, this argues that one of music’s most powerful uses is that it allows us to exercise our emotions in a group situation without damaging consequences. 106 For Cross, music’s defining peculiarity is that every member of a group can be emotionally affected by it in a different way without anyone being aware of the differences. Individuals find meanings in music that seem true for themselves while believing that they are having a powerful shared experience with others. And this makes music uniquely effective at creating social cohesion. Indeed it’s impossible to think of anything else that can do this so safely. In social groups of early hominids, where language and social bonds were not yet up to overcoming competing self-interests, musical ability, enabling the strengthening of cooperation and a sense of belonging, would have offered a very considerable survival premium. And so musical ability was selected for. This function still applies, of course. Sharing in music-making and hearing still generates social cohesion, but it works for us too as individuals. Whether in a group or listening alone, music’s very non-specificity allows us to exercise our emotions without having to experience them full-on.
¶124 In the light of these approaches it becomes much easier to understand what musical performance, and especially what instrumental performance, is doing to us. It allows us to experience a range of feelings that don’t have to be attributed to specific causes, other than the sounds themselves, but that nevertheless allow us to exercise our emotions in satisfying ways. Expressive gestures in performance are stimuli to which we respond in subtle changes of core affect generated by the performer’s view of the changing musical structure. For performance analysts, then, one task is to show how gestures in sound alter core affect. Another could be to try to show what kinds of emotional experiences result from those changes, although the chances of arriving at attributions on which every listener can agree are not great. Fortunately that is exactly the point: music is not meant to be specific; its strength is its flexibility, what I’ve called its unfixedness. And so the most useful task for students of performance may be to show how these attributions are reached: the process is much more important than the results for any one individual.
¶125 A basic objection to the idea that we respond to the evocation of an emotion, rather than to the emotion itself, however, comes from the practical experience of music therapists who find that music does indeed cause real emotions to be felt by participants. In fact that is precisely why music therapy works. Through it, music organises emotions that are otherwise chaotically confused or inaccessible. Why not for the rest of us? It seems probable that in socialised listeners, used to the idea of sitting still and responding internally to (classical!) music, the mapping of recognised onto felt emotion is not always one-to-one. Studies of this are at an early stage, but early experimental work confirms music lovers’ experience that felt emotions in response to music are stronger than recognised emotions when pleasurable but weaker, or even opposite, when not. 107 Through a process yet to be unravelled, we seem to find for negative recognised emotion a positive response. But it certainly remains salutary to more distanced theories of musical response that, for listeners not protected by socialised behaviour in emotional situations, music generates emotional states like nothing else.
¶126 Given the present state of research, we shall have to accept that answers to this puzzle will come not from intense contemplation of it but rather from studying the brain functions that coincide with music. Until then, we may have to be content with the knowledge that mimesis is in process. Musical sounds are like sounds from life and we recognise the likeness. Even the smallest adjustments of speed or loudness or pitch interact with the musical structure to being meaning to a performance. They don’t have to be made on the scale of a Cortot or Lehmann to do expressive work. I hope this will offer good reason for future work to look more closely at less overtly expressive performances. Starting with the most obvious performers makes sense in that it allows us to see most easily what sorts of processes are involved. But in the end it’s the more typical, in terms of runaway selection the ritualised situations in which performers work around a mean, that we should hope to come to understand well.
Footnotes
- 1.
- HMV C 2535, matrix 2B3427‑2 (rec. 20 June 1932), c. 1’28”– 1’35” (1’30”–1’37” in Sound File 26 (wav file)): ‘seest it in the wave of the golden corn’. Back to context...
- 2.
- Four collections of essays that between them cover most of these topics in music perception are Wallin, Merker & Brown (2000); Juslin & Sloboda (2001); Peretz & Zatorre (2003); and ed. Dorothy Miell, Raymond Macdonald & David J. Hargreaves, Musical Communication (Oxford University Press, 2005). For a more detailed discussion of the brain's response to these sorts of codes see Daniel Leech-Wilkinson, 'Listening and responding to the evidence of early twentieth-century performance', Journal of the Royal Musical Association, 134, Special Issue no. 1 (2010), 45-62. Back to context...
- 3.
- When I say ‘over time’ I don’t have any lower limit in mind. A gesture, in my use of the term, may last a few microseconds or (conceivably, as in the case of a prolonged ritardando) several minutes, although most examples here could be measured in tens or hundreds of microseconds (hundredths of a second). Others may wish to distinguish between effects that are perceived as almost instantaneous, and see those as accentuation, and effects that last countable lengths of time, as see only those as gestures. For me, though, that would be to miss the shaped nature of even the briefest musical events. On gestures accompanying speech see especially Susan Goldin-Meadow, Hearing Gesture: how our hands help us think (Cambridge, Mass: Harvard University Press, 2003) and David McNeill, Hand and Mind: what gestures reveal about thought (Chicago: University of Chicago Press, 1992). On gestures in dance and music see Stephen Malloch, ‘Why do we like to dance and sing?’ in ed. Robin Grove, Catherine Stevens and Shirley McKechnie, Thinking in Four Dimensions: creativity and cognition in contemporary dance (Melbourne University Publishing, 2004), 14-28. For a wide range of work with the concept of gesture in music see ed. Anthony Gritten and Elaine King, Music and Gesture (Aldershot: Ashgate, 2006) and Proceedings of the Second Conference on Music and Gesture [CD-ROM of abstracts] (Hull: GK Publishing, 2006). I plan to consider in a separate study the close similarities between my 'expressive gestures' and Daniel Stern's 'vitality affects' (Daniel Stern, The Present Moment in Psychotherapy and Everyday Life (New York: Norton, 2004). Back to context...
- 4.
- Carl Seashore, Psychology of Music (New York: McGraw Hill, 1938; Dover repr. 1967), 9. See Cook (1990), 157, quoting Pandora Hopkins, on why 'deviation' is completely the wrong notion here; also Clarke (1995), 22-3. Back to context...
- 5.
- Clarke (1995), 22, discusses a previous statement of this idea. Even the local norm is going to be perceived somewhat differently by each listener, of course, but that does not invalidate its effect for each. Stern (2004) is entirely about the now moment, and makes much use of music to explain how we perceive it. Back to context...
- 6.
- There are many good textbooks on acoustics and psycho-acoustics. My main sources were Handel (1999); and ed. Perry R. Cook, Music, Cognition, and Computerized Sound: an introduction to psychoacoustics (Cambridge, Mass.: MIT Press, 1999). See also James Beament, How we Hear Music: the relationship between music and the hearing mechanism (Woodbridge: Boydell, 2001). On the acoustics of the voice see especially Johan Sundberg, The Science of the Singing Voice (Dekalb: Northern Illinois University Press, 1987), and his shorter treatment in 'Where does the sound come from?' in ed. John Potter, The Cambridge Companion to Singing (Cambridge University Press, 2000), 231-247. For a better understanding of the speech components of singing see, for example, John Clark & Colin Yallop, An Introduction to Phonetics and Phonology (Oxford: Blackwell, 2nd ed. 1995). Back to context...
- 7.
- Music examples and charts showing the harmonic series are easily available. At the time of writing there is a good description and illustration in http://en.wikipedia.org/wiki/Harmonic_series_(music) (accessed 12 September 2007). Back to context...
- 8.
- Seashore (1938), 251, reports early research suggesting 0.01, but see John Pierce, ‘Hearing in time and space’, in ed. Perry R. Cook (1999), 89-103 at 95; and Clarke (1999). Back to context...
- 9.
- Marcella Sembrich (acc. Frank La Forge), extract from Schubert, ‘Wohin?’, from 'The Record of Singing [I]', EMI RLS 724 (rec. 1908, this LP reissue 1977), record 1, side 1, band 8 (from unpublished matrix no. C 5046, rec. Camden, USA, 30.9.1908), 0’ 48” – 1’ 0.9”. On Sembrich see Stephen Herx, ‘Marcella Sembrich: a legendary singer’s career rediscovered’, The Record Collector 44 (1999), 2-38; W.R. Moran, ‘The recordings of Marcella Sembrich’, The Record Collector 18 (1969), 110-138; and B.E. Steinberg , ‘Marcella Sembrich’, The Record Collector 4 (1949), 105-8. Back to context...
- 10.
- Nigel Rogers (acc. Richard Burnett), extract from Schubert, ‘Wohin?’, from Telefunken 6.35 266-1 (issued 1975), record 1, side 1, band 2, 0’ 51” – 1’ 2.75” Back to context...
- 11.
- Peter Schreier (acc. András Schiff), extract from Schubert, ‘Wohin?’, from Decca 430 414-2 (rec. 1989, issued 1991), track 2, 0’ 59” – 1’ 13” Back to context...
- 12.
- Vocalion C 0220, matrix 03545X, rec. 29 May 1924. Back to context...
- 13.
- A cent is 1/100th of an equally-tempered semitone. It’s a useful measure of pitch not only because it’s an extremely small unit (below the perceptual threshold), so measurements in cents can be very precise, but also because it remains constant across the frequency spectrum, whereas the size of a semitone in cycles per second (Hertz, or Hz) doubles with every ascending octave. Back to context...
- 14.
- Interestingly, in the light of his praise for the 1911 performance quoted earlier, Desmond Shawe-Taylor, one of the most acute critics of early recorded song, was disappointed in those made with Harold Craxton. ‘I have never been able to warm greatly to these records. Like the 1925 acoustic HMVs, they belong to a period when her voice may have been temporarily off colour; they show neither the youthful vividness of the early series not the assured mastery of the early electrics.’ Shawe-Taylor (1987), 179. Plack (2008) discusses changes in Gerhardt’s portamento between earlier and later recordings (p. 109), and rubato (111-16). Back to context...
- 15.
- HMV: matrix Ak17387e, recorded on 19 Jan 1914, issued on HMV 7-42006; Columbia: matrix WA6893-1, rec. 1 Feb 1928, issued on Columbia D 1621. Back to context...
- 16.
- ‘Sir George Henschel: complete commercial recordings’, Cheyne Records CHE 44379, issued 2007. Back to context...
- 17.
- Plack finds many similarities, too, between Henschel’s re-recordings, but also occasional but striking differences. Plack (2008), esp. 137-47. Back to context...
- 18.
- Richard Turner, in ‘Conductors compared: individual interpretation and historic trends in Brahms’s First Symphony’ (a paper at the 2007 CHARM/RMA annual conference), showed with statistical evidence derived from tempo tapping, the exceptional similarity of two recordings by Stokowski made 36 years apart. Klemperer, on the other hand, in this respect changed his performance a great deal over three recordings 28 years apart. Back to context...
- 19.
- For evidence that performers can repeat performances see L. Henry Shaffer and Neil Todd, 'The interpretive component in musical performance', in ed. Alf Gabrielsson, Action and perception in rhythm and music (Stockholm: Publications issued by the Royal Swedish Academy of Music, no. 55, 1987), 139-52. The Joyce Hatto deception―in which recordings by a variety of pianists, previously issued by other companies, were illegally reissued by Concert Artists ascribed to the owner's wife, Joyce Hatto―was unmasked because of the statistically impossibly similarity of the performances. See http://www.charm.kcl.ac.uk/projects/p2_3_2.html. Michael Krausz, in writing philosophically about interpretation, implicitly uses the similarity of performances by one artist to argue that interpretation and performance exist on different levels: ‘different performances may be of a given interpretation’ (Krausz (1993), 75), and ‘Whatever idiosyncrasies there might be between different actual performances, if conceptions of the work are appreciably unchanged, they may perform the same interpretation on different occasions’ (76). This is neat, and may be useful if it proves to be the case (as it well may) that all performances by the same musician are more alike than any performance by another. As formulated here it also requires an unduly text-based notion of the identity of the work, but one could perhaps replace that with a notion of the coherent identity of the performer and still be able to show that performers do indeed have their own interpretations in more or less Krausz’s sense. Back to context...
- 20.
- Daniel Levitin and Perry R. Cook, ‘Memory for musical tempo: additional evidence that auditory memory is absolute’, Perception and Psychophysics 58 (1996), 927-35. Back to context...
- 21.
- See the valuable introduction and survey in Eric Clarke, ‘Empirical methods in the study of performance’, in ed. Eric Clarke and Nicholas Cook, Empirical Musicology: aims, methods, prospects (Oxford University Press, 2004), 77-102. Back to context...
- 22.
- Nicholas Cook, 'The conductor and the theorist: Furtwängler, Schenker and the first movement of Beethoven's Ninth Symphony', in Rink (1995), 105-25. Back to context...
- 23.
- Taruskin (1995), 222-6; and 'Resisting the Ninth', 19 th-Century Music 12 (1989), 241-56, repr. in Taruskin (1995), 235-61. Back to context...
- 24.
- Bowen (1999), 424-51, esp. 434-6 & 446-50. Back to context...
- 25.
- Matrix 2EA13523-1, rec. 30 December 1948, issued on HMV C 3908, 1’ 15” – 2’ 38”. This set of all all the Preludes has an intriguing recording history. Matrices 2EA13517-1 & 18-1 (C 3905), 19-1 & 20-2 (C3906), and 21-1 (C 3907), were all recorded on 29 December 1948, and this single item (23-1 (C 3908)) in its first usable take the following day. But the remaining two sides, 2EA13522-3 (C 3907) & 24-4 (C 3908), were made on 20 September 1949, very soon before the set was issued. The high take numbers show that either two waxes were damaged during production or (less likely in view of the very late date) those two performances were felt to be sub-standard. Back to context...
- 26.
- Repp (1992b), 244, explains why we may not notice this. Back to context...
- 27.
- Much of this book was written using other, now superceded programs. Following them, Sonic Visualiser has been through numerous versions (mostly beta) already, and no doubt will have changed in important ways by the time you read this, so be prepared for the instructions here to be outdated. As Carl Seashore said of similar work back in 1932, ‘Developments in this field have come so fast that one of our special joys in the laboratory has been that of scrapping instruments.’ (ed. Seashore (1932), 7.) Back to context...
- 28.
- Source details as for Sound File 13 (wav file), but with fractionally more noise reduction. For a more detailed study of Gerhardt's style, including a statistically-based study of her changing rubato, see Daniel Leech-Wilkinson, 'Performance style in Elena Gerhardt's Schubert song recordings', Musicae Scientiae (forthcoming, 2010). Back to context...
- 29.
- When Harold Seashore had explained the notation of his performance graphs—the precursors of SV displays—in 1936 he advised that, ‘Before going further into a study of the vocal performances, the reader is advised to sing the Ave Maria [Gounod/Bach’s] through several times while scanning the graphic picture of it. He will quickly grasp the significance of this type of recording and also will have an experience of literally both hearing and seeing the song.’ (H. Seashore (1936), 24.) While we enjoy the luxury of being able to listen to an SV display played back by the computer, I don’t discourage the reader from singing through ‘An die Musik’ at this point, especially if you attempt to imitate Elena Gerhardt. It puts things into perspective. Back to context...
- 30.
- Bowen (1999), esp. 449. Back to context...
- 31.
- For more about this research see http://www.mazurka.org.uk/ . Back to context...
- 32.
- For a good introduction to sound analysis for musicologists see Stephen McAdams, Philippe Depalle & Eric Clarke, 'Analyzing musical sound', in ed. Eric Clarke and Nicholas Cook, Empirical Musicology: aims, methods, prospects (Oxford University Press, 2004), 157-96. Back to context...
- 33.
- For a different approach to spectrographic analysis, using customised routines in MATLAB, see Johnson (1999), 69-84. Back to context...
- 34.
- This material was used also in the online SV tutorial at http://www.charm.kcl.ac.uk/analysing/p9_0_1.html. Back to context...
- 35.
- Matrix A21072, issued on HMV DB 1047 (rec. 1926), 1’ 04” – 1’ 24” Back to context...
- 36.
- SV 1.2 settings: Threshold 0, Colour Rotation 42, Scale dBV^2, both boxes unchecked, Gain 4.5dB, Window 2048, 75%, All Bins, Linear; Vertical zoom 5500, Horizontal zoom 44. Back to context...
- 37.
- Matrix A49209-1A, issued on HMV DB 1297 (rec. 1928), 1’ 07” – 1’ 28”. Back to context...
- 38.
- Philip (1992), 176-8, compares McCormack's and Heifetz's (and others') portamento in these recordings. On McCormack see Brian Fawcett-Johnston, ‘John Count McCormack’, The Record Collector 29 (1984), 5-68 & 77-107. Back to context...
- 39.
- See especially Reuven Tsur, What Makes Sound Patterns Expressive? (Duke University Press, 1992), 42-3. Back to context...
- 40.
- From Handel (1999), 70. Back to context...
- 41.
- Handel (1999), 70, 318, 519. For early attempts at generating readout from records see George Brock-Nannestad, ‘Sound carriers for scientific audio recording and analysis 1857-1957’, preprint of paper delivered to the Audio Engineering Society’s 106th convention, 1999 (AES Preprint 4884). Back to context...
- 42.
- Matrix WA10984-2 (rec. 16 December 1930), issued on Columbia DB 563. Back to context...
- 43.
- If you try this with ‘All bins’ then measure from the exact middle of the band of colour representing the frequency: everything else is an artefact of the way spectrograms are calculated, not real information about sounding pitch. Back to context...
- 44.
- Though it seems more than likely that as techniques are developed for this we shall discover that quite small details of portamento have perceptual relevance. For an impressive start in this direction see H. Seashore (1936), esp. 57-74. Back to context...
- 45.
- Harold Seashore (H. Seashore (1936), 60-2) devised a consistent approach to dealing with this problem, but it remains to be determined how listeners distinguish (or could distinguish with confidence) between slide and note. Back to context...
- 46.
- Metfessel (1932), 53-5, showed this in an early experiment. Back to context...
- 47.
- For early studies see Joseph Tiffin, ‘The role of pitch and intensity in the vocal vibrato of students and artists’, in ed. Seashore (1932), 134-165; ed. Seashore (1936), 71-5; and H. Seashore (1936), 94-7. Intensity vibrato on the violin is examined in Arnold M. Small, ‘An objective analysis of artistic violin performance’, in ed. Seashore (1936), 172-231 at 211-20. Back to context...
- 48.
- Note that in Sonic Visualiser the size of the waveform can be varied with the vertical grey dial provided that the waveform tab is selected. Back to context...
- 49.
- D.A. Rothschild, ‘The timbre vibrato’, in ed. Seashore (1932), 236-44; Harold G. Seashore, ‘The hearing of pitch and intensity in vibrato’, in ed. Seashore (1932), 213-35; ed. Seashore (1936), 76-81. Back to context...
- 50.
- Note that in SV when playback is slowed down a lot, as here, the ‘now’ bar lags far behind the playback, so ignore it and match what you see to what you hear. You’ll be able to find your place quite easily at the start and end of each repeated loop of the extract. Back to context...
- 51.
- As the French text is quite hard to find I give it here from a valuable article by Xavier Hascher which also includes details of the editions and orchestration: ‘Quand Schubert «entra dans la gloire»: Adolphe Nourrit et les versions orchestrées de La jeune religieuse et du Roi des Aulnes’, Cahiers Franz Schubert 17 (October 2000), 30–70: l’Orage grossit et s’avance en grondant / Les murs ébranlés sont battus par le vent / l’éclair brûle au loin l’horizon pâlissant / Puis partout l’ombre / et la nuit somber / deuil et terreur / souvenir de douleur / l’orage ainsi grondait en mon Coeur / l’amour délirant nuit et jour m’agitait / au son d’une voix tout mon corps frissonnait, / et comme l’éclair un regard me brûlait / ainsi flétrie / ma triste vie / se consumait / Orage à présent gronde avec fureur / la paix est rentrée / à jamais dans ce Coeur / la Vierge vouée / à l’amour du Seigneur / lui donne son âme épurée / qu’embrase de ses feux la divine ferveur / j’attends à genoux les promesses du ciel / descends ô mon sauveur du séjour eternal / et viens m’affranchir des liens de la terre / mais l’air retentit des chants de la prière / au pied de l’autel fume l’encens / la nef se remplit de saints accents / célestes concerts, accords puissants / venez ravir mon âme et soumettre mes sens / Alleluia! Alleluia! Back to context...
- 52.
- Metfessel (1932), 60-2. Back to context...
- 53.
- Metfessel (1932), 112-14. Back to context...
- 54.
- Leech-Wilkinson (2001), 7-8. Back to context...
- 55.
- Matrix AS 2, issued in the USA as L’Oiseau Lyre AS 8, side b (1935). Back to context...
- 56.
- Lotte Lehmann (acc. Paul Ulanowsky), Schubert, ‘Die junge Nonne’, matrix XCO 30013-1 (rec. 4 Mar 1941), issued on Columbia 71509-D / Columbia LOX 654, 0’51”–1’12”. Back to context...
- 57.
- US Columbia sides at this time were dubs, hence the poor sound. I discussed this example (without a sound file) in Leech-Wilkinson (2006a). Back to context...
- 58.
- I discussed this at length in Leech-Wilkinson (2007), though without using the Lehmann performance as an example. Back to context...
- 59.
- On the common origins of music and speech see especially Steven Mithen, The Singing Neanderthals: the origins of music, language, mind and body (London: Weidenfeld & Nicolson, 2005), and Steven Brown, ‘The “Musilanguage” model of music evolution’, in Wallin et al. (2000), 271-300. On the very close relationship between the vocal and musical expression of emotion see especially Patrik N. Juslin and Petri Laukka, ‘Communication of emotions in vocal expression and music performance: different channels, same code?’, Psychological Bulletin 129 (2003), 770-814. Back to context...
- 60.
- Leech-Wilkinson (2006a). Back to context...
- 61.
- ‘Schubert Lieder’, Kathleen Battle and James Levine, DG 419 237-2 (recorded 1985 & 87), track 13, 0’9”–0’17”. © Polydor International GmbH, Hamburg 1988 Back to context...
- 62.
- Gabrielsson & Juslin (2003), 528. Back to context...
- 63.
- Battle & Levine, track 14, 0’13”–0’19”. © Polydor International GmbH, Hamburg 1988 Back to context...
- 64.
- Battle & Levine, track 11, 0’ 28” – 0’ 38”. © Polydor International GmbH, Hamburg 1988 Back to context...
- 65.
- Alvin M. Liberman and Ignatius G. Mattingly, 'The motor theory of speech perception revised', Cognition 21 (1985), 1-36. Back to context...
- 66.
- Juslin (2001). Back to context...
- 67.
- John Sloboda, 'Does music mean anything?', Musicae Scientiae 2 (1998), 21-32; reprinted in Sloboda, Exploring the Musical Mind: cognition, emotion, ability, function (Oxford University Press, 2005), 163-72. Back to context...
- 68.
- Arnie Cox, 'The Mimetic Hypothesis and Embodied Musical Meaning', Musicae Scientiae 5 (2001), 195‑212. Back to context...
- 69.
- Watt & Ash (1998). Back to context...
- 70.
- Peter Kivy, Sound Sentiment: an essay on the musical emotions, including the complete text of The Corded Shell (Philadelphia: Temple University Press, 1989). Back to context...
- 71.
- Stephen Davies, Musical Meaning and Expression (Ithaca: Cornell University Press, 1994), esp. chapter 5. Back to context...
- 72.
- This transfer is of matrix 2-20726, issued Parlophon P 9662, rec. 24 April 1928. Transfer © Roger Beardsley 2007. For an appreciation of Seinemeyer’s recorded output see Vicki Kondelik, ‘Meta Seinemeyer’, The Record Collector 47 (2002), 243-83. Back to context...
- 73.
- Battle & Levine, track 15, 0’35”–0’38”. © Polydor International GmbH, Hamburg 1988 Back to context...
- 74.
- Battle & Levine, track 15, 0’52”–1’10”. © Polydor International GmbH, Hamburg 1988 Back to context...
- 75.
- My approach does not depend on the existence of so-called 'basic emotions', (on which see Andrew Ortony & Terence J. Turner, 'What’s basic about basic emotions?', Psychological Review 97 (1990), 315-31) nor on a universal set of emotions shared by all. At the other extreme I suspect that William M. Reddy has over-estimated the extent to which emotions are culturally constructed. (The Navigation of Feeling: a framework for the history of emotions (Cambridge University Press, 2001)). His historical study of changing feelings, however, is thought-provoking. (I am grateful to Jeanice Brooks for pointing me towards his work.) Back to context...
- 76.
- Nussbaum (2007), 231-2, argues that in such situations music can model the bodily movements of the observer taking in or later describing the awesome object, and that the listener shifts back and forth between the viewpoints of observer and observed. Back to context...
- 77.
- Susan Metcalfe-Casals (acc. Gerald Moore), Schubert, ‘Die junge Nonne', matrix CTPX 3884-1, issued on HMV JG 20, rec. 7 July 1937. Back to context...
- 78.
- 'Beethoven's last piano sonata and those who chase crocodiles: cross-domain mappings of auditory pitch in a musical context', summarised in ed. Mario Baroni, Anna Rita Addessi, Roberto Caterina & Marco Costa, 9th International Conference on Music Perception and Cognition, 6th Triennial Conference of the European Society for the Cognitive Sciences of Music: Abstracts (University of Bologna, August 22-26, 2006), 286-7. Back to context...
- 79.
- Lula Mysz-Gmeiner (alto) accompanied by Julius Dahlke (piano), mat. 289/90 br, rec. June 1928, issued on B 44148/9, Polydor 21455. I am grateful to Karsten Lehl for a flat transfer. This performance is discussed in detail in Leech-Wilkinson (2007), 220-29, where the sound file has more (too much) noise reduction. Back to context...
- 80.
- As a further example, which readers may like to interpret themselves, Data File 12 (sv file) provides detailed information about Sound File 18 (wav file), Fischer-Dieskau’s 1951 ‘Am Feierabend’, discussed in chapter 4 above. Back to context...
- 81.
- Dietrich Fischer-Dieskau (acc. Gerald Moore), Schubert, ‘Das Fischermädchen’ (Schwanengesang), matrix OEA 15947-2, rec. 6 October 1951, issued on HMV DA 2045. transfer © King’s College London 2007. A note on how this table works: each line of the poem is given complete in italics in the left column, with a translation in the middle column; beneath that, the first column picks out of the line in italics the words Fischer-Dieskau emphasises in his performance, the middle column describes what he does in sound to produce the emphasis, and the right column suggests what this may signal to the listener. Back to context...
- 82.
- To test this we need more refined versions of the experiments that lie behind Patrik Juslin's table of the musical correlates of basic emotions (Juslin (2001), 315). Back to context...
- 83.
- Schwarzkopf (2002), 88. Back to context...
- 84.
- Handel (1999), 378. Back to context...
- 85.
- For a condensed survey see John C.M. Brust, 'Music and the neurologist: a historical perspective', in Peretz & Zatorre (2003), 181-91 at 184. On music's usefulness in treating stoke patients see Michael H. Thaut, 'Rhythm, human temporality, and brain function', in ed. Miell et al (2005), 171-91. Back to context...
- 86.
- Leech-Wilkinson (2006a), 62-3. Back to context...
- 87.
- Elaine Hatfield, John T. Cacioppo & Richard L. Rapson, Emotional Contagion (Cambridge University Press, 1994). See also Juslin (2001), 329. Back to context...
- 88.
- See especially Sloboda (1998). Back to context...
- 89.
- For evidence for the close relatedness of the vocal and musical expression of emotion see Juslin & Laukka (2003). And on the likelihood that cues conveying specific emotions derive from speech cues see Juslin (2003), 294. Back to context...
- 90.
- This is not the place to rehearse past debates, stretching back to the 18th century and beyond, about the origins of music. At the moment it’s widely accepted that singing and speech are much older than musical instruments, with a consensus in favour of seeing music and speech as specialised adaptations of pre-linguistic vocal communication inherited from our primate ancestors. (See especially Mithen (2005); Brown (2000); Steven Brown, 'Contagious heterophony: a new theory about the origins of music', Musicae Scientiae 11 (2007) 3-26; Bruce Richman, 'How music fixed "nonsense" into significant formulas: on rhythm, repetition, and meaning', in Wallin et al. (2000), 301-14). This would, of course, help to explain why instrumental music owes so much of its expressive gesturing in sound to the representation of emotional states by the singing voice. Back to context...
- 91.
- Jascha Heifetz, Schubert, ‘Ave Maria’ (arr. violin and piano), matrix A21072, issued on HMV DB 1047 (rec. 1926). Back to context...
- 92.
- For readers who wish to test this here are Scott's remaining stanzas: Ave, Maria! Undefiled! / The flinty couch we now must share, / Shall seem with down of eider piled / If Thy, if Thy protection hover there. / The murky cavern's heavy air / Shall breath of Balm if thou hast smiled; / Then, Maiden hear a maiden's prayer. / Oh Mother, hear a suppliant child! / Ave Maria! / Ave, Maria! Stainless styled! / Foul demons of the earth and air, / From this their wonted haunt exiled, / Shall flee, shall flee before thy presence fair. / We bow us to our lot of care / Beneath Thy guidance reconciled, / Hear for a maid a maiden's prayer; / And for a father bear a child! / Ave Maria! Back to context...
- 93.
- Heifetz also waters down Wilhelmj’s arrangement in a number of respects, bringing it closer to Schubert’s score. Back to context...
- 94.
- Which might on occasion be expectation for a change, in which case no change would be the expressive gesture. Back to context...
- 95.
- Alf Gabrielsson & Siv Lindström Wik, ‘Strong experiences related to music: a descriptive system’, Musicae Scientiae, 7 (2003), 157-217; Alf Gabrielsson, 'Emotions in strong experiences with music', in Juslin & Sloboda (2001) 431-49. Back to context...
- 96.
- See also Tia DeNora, Music in Everyday Life (Cambridge University Press, 2000). Back to context...
- 97.
- For a good introduction see Jacqueline Schmidt Peters, Music Therapy: an introduction (Springfield, IL.: Charles C. Thomas, 2nd rev. ed. 2000) and for an excellent overview of research, ed. William B. Davis, Michael H. Thaut, & Kate E. Gfeller, An Introduction to Music Therapy: theory and practice (2nd rev. ed., Boston: McGraw-Hill, 1998). On the wider range of music therapies see ed. Tony Wigram, Jos De Backer, & Colwyn Trevarthen, Clinical Applications of Music Therapy in Developmental Disability, Paediatrics and Neurology (London: Kingsley, 1999); and ed. David Aldridge, Music Therapy and Neurological Rehabilitation: performing health (London: Kingsley, 2005). Back to context...
- 98.
- Kari Batt-Rawden, Susan Trythall and Tia De Nora, 'Health musicking as cultural inclusion', in ed. Jane Edwards, Music: Promoting Health and Creating Community in Healthcare Contexts (Cambridge: Cambridge Scholars Press, 2007), 64-82. See also ed. David Aldridge, Music Therapy in Dementia Care (London: Jessica Kingsley, 2000). Back to context...
- 99.
- Labrande & Sturrock (1999), DVD chapter 19, 0hr 56’11”–58’47”. Back to context...
- 100.
- Matrix 2EA12085-2 (rec. June 1947), 0’55”–3’40”, issued on HMV DB 6502. Back to context...
- 101.
- Matrix 2EA2140-1 (rec. 4 July 1935), 0’48”–3’23”, issued on HMV DB 2581. Back to context...
- 102.
- Lehmann recorded the cycle twice, Baker at least three times. The versions I am thinking of are Lehmann (with an instrumental trio conducted by Frieder Weissmann) on Parlophone RO 20090/93 (rec. 10 Nov 1928), reissued on Pearl GEMM CD 9119, and Baker (with Martin Isepp) on Saga XID 5277 (rec. 1966). Back to context...
- 103.
- On the evolution of musical ability see especially: Nicholas Bannan, 'Music in human evolution: an adaptationist approach to voice acquisition', PhD thesis, University of Reading, 2002; Mithen (2005); Wallin et al. (2000); Ian Cross, 'Music and cognitive evolution', in Robin Dunbar & Louise Barrett (eds.), The Oxford Handbook of Evolutionary Psychology (Oxford University Press, 2007), 649-67. Back to context...
- 104.
- Miller (2000); see chapter 7 above. Back to context...
- 105.
- James A. Russell, 'Core affect and the psychological construction of emotion', Psychological Review 110 (2003), 145-72. Back to context...
- 106.
- Ian Cross, ‘The evolutionary nature of musical meaning’, Musicae Scientiae (forthcoming); and, ‘Music and meaning, ambiguity and evolution’, in ed. Miell et al (2005), 27-43. Back to context...
- 107.
- Kari Kallinen & Niklas Ravaja, ‘Emotion perceived and emotion felt: same and different’, Musicae Scientiae 10 (2006), 191-213. Back to context...